Java岗大厂面试百日冲刺【Day8】 —— Redis2
Java岗大厂面试百日冲刺【Day8】 —— Redis2
本文已获得原作者 _陈哈哈 授权并经过重新整理规划后发布。
本栏目Java开发岗高频面试题主要出自以下各技术栈:Java基础知识、集合容器、并发编程、JVM、Spring全家桶、MyBatis等ORMapping框架、MySQL数据库、Redis缓存、RabbitMQ消息队列、Linux操作技巧等。
面试题1:介绍一下你对Redis哨兵模式的了解吧
Redis在主从复制模式下,一旦主节点由于故障不能提供服务, 需要人工将从节点晋升为主节点, 同时还要通知应用方更新主节点地址, 对于很多应用场景这种故障处理的方式是无法接受的,这也是Redis主从复制的缺点之一,没有办法对master进行动态选举。 可喜的是Redis从2.8开始正式提供了Redis Sentinel(哨兵) 机制来解决这个问题。
哨兵模式介绍
- Sentinel(哨兵)进程是用于监控redis集群中Master主服务器工作的状态;
- 在Master主服务器发生故障的时候,可以实现Master和Slave服务器的切换,保证系统的高可用(HA);
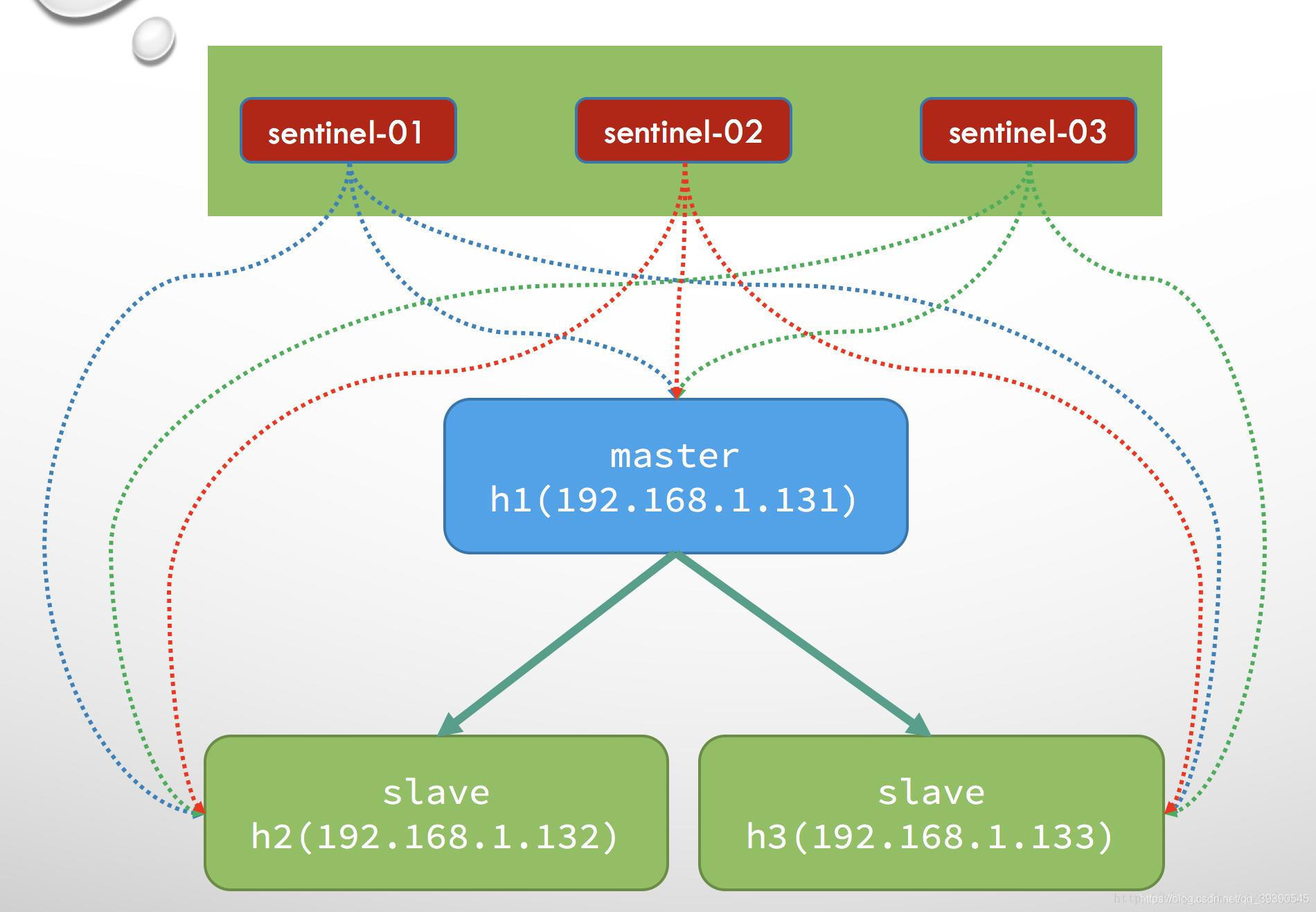
哨兵进程的作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
- 然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
介绍一下Redis故障自动切换过程
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。
那你说一下主观下线以及客观下线的区别吧
主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。
从主观下线状态切换到客观下线状态并没有使用严格的法定人数算法(strong quorum algorithm), 而是使用了流言协议: 如果 Sentinel 在给定的时间范围内, 从其他 Sentinel 那里接收到了足够数量的主服务器下线报告, 那么 Sentinel 就会将主服务器的状态从主观下线改变为客观下线。 如果之后其他 Sentinel 不再报告主服务器已下线, 那么客观下线状态就会被移除。
客观下线条件只适用于主服务器。 对于任何其他类型的 Redis 实例, Sentinel 在将它们判断为下线前不需要进行协商, 所以从服务器或者其他 Sentinel 永远不会达到客观下线条件。
说一下哨兵进程的工作方式吧
- 每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过down-after-milliseconds选项所指定的值,则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)。
- 如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有
- Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态。
- 当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)。
- 在一般情况下, 每个Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
- 当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
- 若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
Redis配置哨兵模式
配置3个哨兵和1主2从的Redis服务器来演示这个过程。
| 服务类型 | 是否是主服务器 | IP地址 | 端口 |
|---|---|---|---|
| Redis | 是 | 192.168.101.90 | 6379 |
| Redis | 否 | 192.168.101.91 | 6379 |
| Redis | 否 | 192.168.101.92 | 6379 |
| Sentinel | - | 192.168.101.90 | 26379 |
| Sentinel | - | 192.168.101.91 | 26379 |
| Sentinel | - | 192.168.101.92 | 26379 |
首先配置Redis的主从服务器,修改redis.conf文件如下
# 使得Redis服务器可以跨网络访问
bind 0.0.0.0
# 设置密码
requirepass "123456"
# 指定主服务器,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置
slaveof 192.168.101.90 6379
# 主服务器密码,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置
masterauth 123456
# 上述内容主要是配置Redis服务器,从服务器比主服务器多一个slaveof的配置和密码。
配置3个哨兵,每个哨兵的配置都是一样的。在Redis安装目录下有一个sentinel.conf文件,copy一份进行修改
# 禁止保护模式
protected-mode no
# 配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义,192.168.101.90代表监控的主服务器,6379代表端口,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行failover操作。
sentinel monitor mymaster 192.168.101.90 6379 2
# sentinel author-pass定义服务的密码,mymaster是服务名称,123456是Redis服务器密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster 123456
关键配置项:
sentinel monitor mymaster 192.168.101.90 6379 2
配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义,192.168.101.90代表监控的主服务器,6379代表端口,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行failover操作。
有了上述的修改,我们可以进入Redis的安装目录的src目录,通过下面的命令启动服务器和哨兵
# 启动Redis服务器进程
./redis-server ../redis.conf
# 启动哨兵进程
./redis-sentinel ../sentinel.conf
注意启动的顺序。首先是主机(192.168.101.90)的Redis服务进程,然后启动从机的服务进程,最后启动3个哨兵的服务进程。
面试题2:redis 的过期策略和内存淘汰策略是一个东西么?
过期策略和内存淘汰策略乍一看相似,但却不是一个事儿。我们知道,往 redis 写入的数据会消失很正常的,在生产环境的 redis 经常会丢掉一些数据,写进去了,过一会儿可能就没了?这不是BUG。因为redis 是缓存,不是数据库。
缓存主要存在内存中,内存空间是有限的,比如 redis 就只能用 10G,你要是往里面写了 20G 的数据,会咋办?当然会干掉 10G 的数据,保留另外 10G 数据。那么干掉哪些数据,保留哪些数据呢?当然要根据热度干掉不常用的数据。
数据已经过期了,怎么还占用着内存?这是由 redis 的过期策略来决定。
Redis 过期策略
在Redis中过期的key不会立刻从内存中删除,而是会同时以下面两种策略进行删除:
- 定期删除:每隔一段时间,随机检查设置了过期的key并删除已过期的key;维护定时器消耗CPU资源;
- 惰性删除:当key被访问时检查该key的过期时间,若已过期则删除;已过期未被访问的数据仍保持在内存中,消耗内存资源;
定期删除
Redis每 100ms 进行一次过期扫描:
- 随机取20个设置了过期策略的key;
- 检查20个key中过期时间中已过期的key并删除;
- 如果有超过25%的key已过期则重复第一步;
这种循环随机操作会持续到过期key可能仅占全部key的25%以下时,并且为了保证不会出现循环过多的情况,默认扫描时间不会超过25ms;
惰性删除
定期删除可能会导致很多过期 key 到了时间并没有被删除掉,那咋整呢?所以就是惰性删除了。这就是说,在你获取某个 key 的时候,redis 会检查一下 ,这个 key 如果设置了过期时间那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。
获取 key 的时候,如果此时 key 已经过期,就删除,不会返回任何东西。
但是实际上这还是有问题的,如果定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?如果大量过期 key 堆积在内存里,导致 redis 内存块耗尽了,咋整?
那这就要提到了Redis的内存淘汰机制。
内存淘汰机制
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据,如何淘汰旧数据给新数据腾出内存空间。
redis 内存淘汰机制有以下几个:
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。(这个是最常用的)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
Redis的内存淘汰策略的选取并不会影响过期的key的处理。内存淘汰策略用于处理内存不足时的需要申请额外空间的数据;过期策略用于处理过期的缓存数据。
简单介绍一下LRU淘汰机制吧
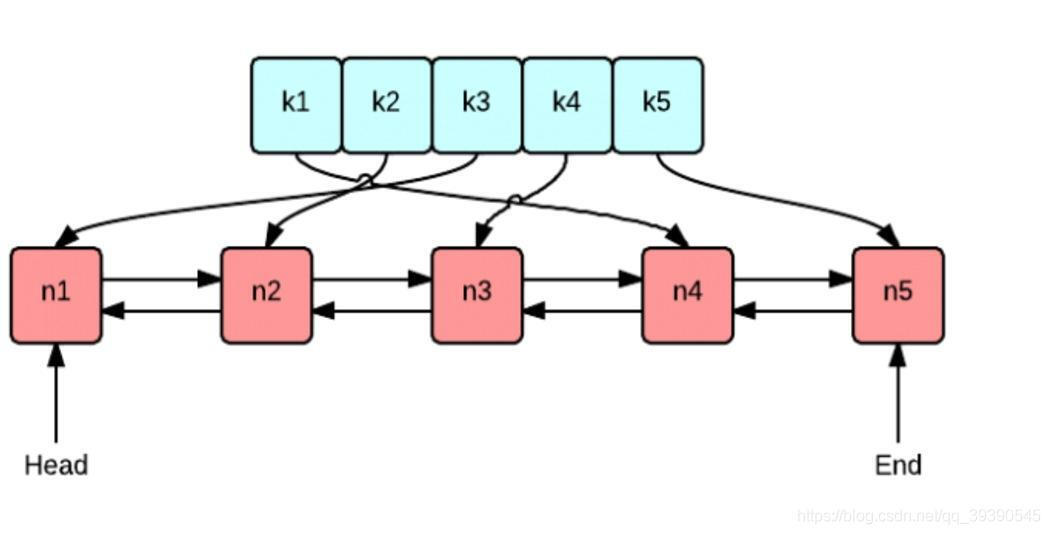
LRU(Least recently used),淘汰最近最少使用的;算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
算法思路:
- 新数据插入到链表头部;
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
- 当链表满的时候,将链表尾部的数据丢弃。
- 在服务器配置中保存了 lru 计数器 server.lrulock,会定时(redis 定时程序 serverCorn())更新,server.lrulock 的值是根据 server.unixtime 计算出来进行排序的,然后选择最近使用时间最久的数据进行删除。另外,从 struct redisObject 中可以发现,每一个 redis 对象都会设置相应的 lru。每一次访问数据,会更新对应redisObject.lru
在Redis中,LRU算法是一个近似算法,默认情况下,Redis会随机挑选5个键,并从中选择一个最久未使用的key进行淘汰。在配置文件中,按maxmemory-samples选项进行配置,选项配置越大,消耗时间就越长,但结构也就越精准。
Redis的内存用完了会发生什么实际问题?
如果达到设置的上限,Redis的写命令会返回错误信息(但是读命令还可以正常返回。)或者你可以配置内存淘汰机制,当Redis达到内存上限时会冲刷掉旧的内容。
Redis如何做内存优化?
可以好好利用Hash,list,sorted set,set等集合类型数据,因为通常情况下很多小的Key-Value可以用更紧凑的方式存放到一起。尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面。
面试题3:在实际生产环境中的 redis 你是怎么部署的?说一服务器情况吧
redis cluster,我们线上是用了 5 台服务器(32G 内存+ 8 核 CPU + 1T 磁盘),每台服务器划了两台虚拟机共10台,5 台机器部署了 redis 主实例,另外 5 台机器部署了 redis 的从实例, 每个主实例挂了一个从实例,5 个节点对外提供读写服务,每个节点的读写高峰 qps 可能可以达到每秒 5 万,5 台机器最多是 25 万读写请求/s。
分配给 redis 进程的内存是 10g,一般线上生产环境,redis 的内存尽量不要超过 10g,超过 10g 可能会有问题,5 台机器对外提供读写,一共有 50g 内存。
因为每个主实例都挂了一个从实例,所以是高可用的,任何一个主实例宕机,都会自动故障迁移,redis 从实例会自动变成主实例继续提供读写服务。
我们主要存的是热点商品数据,每条数据是 10kb。100 条数据是 1mb,10 万条数据是 1g。常驻内存的是 200 万条商品数据,占用内存是 20g,仅仅不到总内存的 50%。目前高峰期每秒就是 3500 左右的请求量。