Java岗大厂面试百日冲刺【Day34】—— 消息队列2
Java岗大厂面试百日冲刺【Day34】—— 消息队列2
本文已获得原作者 _陈哈哈 授权并经过重新整理规划后发布。
本栏目Java开发岗高频面试题主要出自以下各技术栈:Java基础知识、集合容器、并发编程、JVM、Spring全家桶、MyBatis等ORMapping框架、MySQL数据库、Redis缓存、RabbitMQ消息队列、Linux操作技巧等。
面试题1:我们知道MQ有可能发生重复消费,啥导致的?
在一般网络环境下,都存在一定的网络延迟、网络抖动,网络问题导致消息重复发送的情况是难以避免的,毕竟网络环境无法预知,因此MQ默认允许消息重复发送。是的,只要通过网络交换数据,就无法避免这个问题。秉承着打不过就加入的原则,解决这个问题的办法就是绕过这个问题。
那么问题就变成了:如果消费端收到两条一样的消息,应该怎样处理?
RabbitMQ、RocketMQ、Kafka,都有可能会出现消息重复消费的问题。因为这问题通常不是 MQ 自己保证的,而是消费方自己来保证的。
比如说Kafka, 他实际上有个 offset 的概念(偏移量),就是每个消息写进去,都有一个 offset,代表消息的序号,然后 consumer 消费了数据之后,每隔一段时间(定时定期),会把自己消费过的消息的 offset 提交一下。代表我已经消费过了,就算消费者重启,Kafka也会让消费者继上次消费到的offset继续消费。
场景示例:
kafka 中有一条数据:A、B,kafka给这条数据分一个 offset(偏移量),offset为: 1001、1002。消费者从 kafka 去消费的时候,也是按照这个顺序去消费。当消费者消费到 offset=1002 的这条数据(此时offset=1001还没消费完),刚提交 offset=1002 到 zookeeper,消费者进程就被重启了。此时消费过的数据 A 的 offset 还没有提交,kafka 也就不知道消费者已经消费了1001这条数据。那么重启之后,消费者会找 Kafka 把上次消费到的那个地方后面的数据继续传递过来。数据 A 再次被消费。
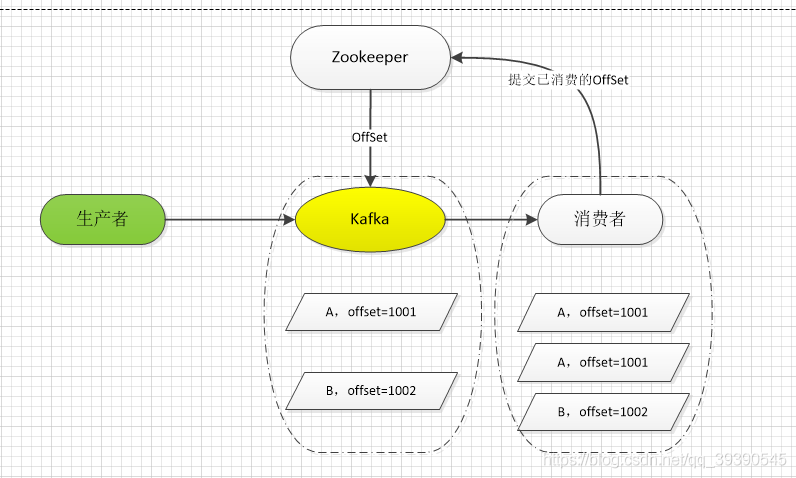
如果消费者是拿到一条数据就往数据库里写一条,就会导致把数据 A 在数据库里插入了 2 次,导致数据不一致。重复消费其实并不可怕,可怕的是你没考虑到重复消费时,怎么保证幂等性。
追问1:如何保证消息不被重复消费?如何实现幂等性?
幂等性,比如一个数据或者一个请求,给后台重复发多次,针对这类情况,你得确保对应的数据结果是不会改变的,不能因为发了多个相同请求导致数据出错。
怎么保证消息队列消费的幂等性?
- 比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update就行。对了,ES的插入接口是不是就采用了
插入并更新的策略?发现相同的数据就直接更新他。 - 如果是写 Redis,那没问题,反正每次都是
set,天然幂等性。 - 比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个
全局唯一的 id,类似订单 id 之类的东西,然后你这里消费到了之后,先根据这个 id 去 Redis 里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个 id 写进Redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。 - 比如基于数据库的
唯一键来保证重复数据不会重复插入多条。因为有唯一键约束了,重复数据插入只会报错,不会导致数据库中出现脏数据。(类似于第一条,可以通过修改SQL,转成插入或更新的策略)
MySQL中的插入或替换、插入或更新、插入或忽略策略,详情可参考《MySQL中特别实用的几种SQL语句送给大家》
面试题2:RabbitMQ如何保证消息的顺序性
消息队列中的若干消息如果是对同一个数据进行操作,这些操作又具有先后关系,必须按顺序执行,否则可能会造成数据错误。
比如有三个请求,是对数据库中的同一条数据进行了插入->更新->删除操作,执行顺序必须保证,如果变成删除->更新->插入就很可笑了,造成最终数据不一致。
顺序错乱的场景:
一个queue,有多个consumer去消费,这样就会造成顺序的错误,consumer从MQ里面读取数据是有序的,但是每个consumer的执行时间是不固定的,无法保证先读到消息的consumer一定先执行完操作,这样就会出现消息并没有按照顺序执行,造成数据顺序错误。
rabbitmq如何保证消息的消费顺序
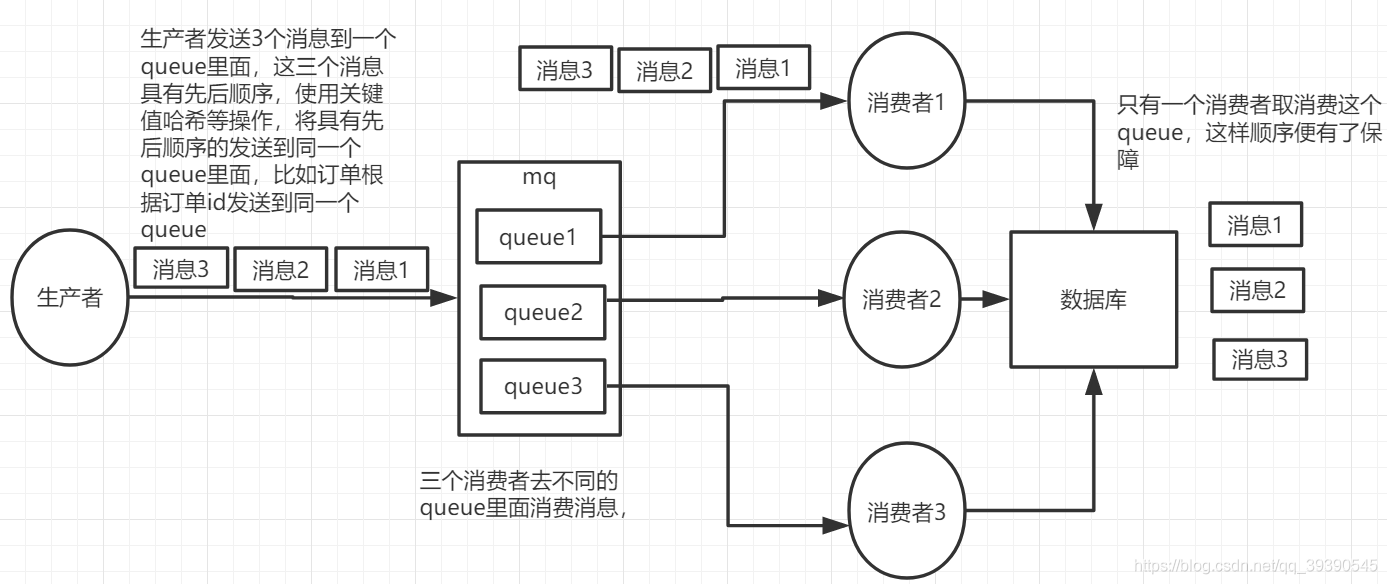
将原来的一个queue拆分成多个queue,每个queue都有一个自己的consumer。该种方案的核心是生产者在投递消息的时候根据业务数据关键值(例如订单ID哈希值对订单队列数取模)来将需要保证先后顺序的同一类数据(同一个订单的数据) 发送到同一个queue当中,让同一个consumer来按顺序处理。
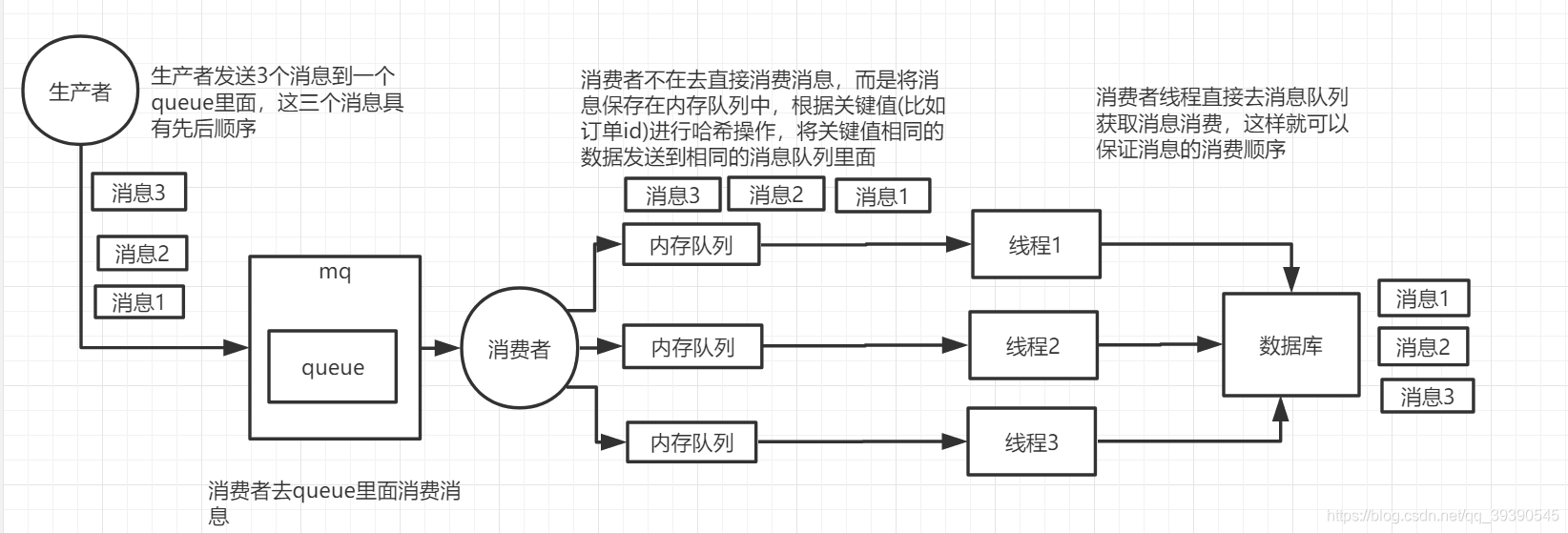
一个queue就一个consumer,在consumer中维护多个内存队列,根据业务数据关键值(例如订单ID哈希值对内存队列数取模)将消息加入到不同的内存队列中,然后多个真正负责处理消息的线程去各自对应的内存队列当中获取消息进行消费。
RabbitMQ保证消息顺序性总结:
核心思路就是根据业务数据关键值划分成多个消息集合,而且每个消息集合中的消息数据都是有序的,每个消息集合有自己独立的一个consumer。多个消息集合的存在保证了消息消费的效率,每个有序的消息集合对应单个的consumer也保证了消息消费时的有序性。也就是保证了生产者 - MQServer - 消费者是一对一对一的关系。
面试题3:消息队列满了以后该怎么处理?比如现在大量消息在MQ里长时间积压,你会如何解决?
这种就是问的实际业务场景中的问题,这种情况原因一般是:消费者consumer出了bug或性能问题,消费量远低于消息增量。导致消息积压越来越多,几百万至上千万,就算consumer及时恢复,也要吃几个小时才能吃完。同时,已经出现部分积压的消息过期失效,丢失了数据。
这时候首先想到的是横向扩consumer,先把这些消息尽快吃掉再说。。具体如下:
- 先修复consumer的问题,确保其恢复消费速度,然后将现有cnosumer都停掉;
- kafka的话,比如新建一个topic,partition是原来的10倍,临时建立好原先10倍或者20倍的queue数量;
- 写一个临时的分发数据的consumer程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的10倍数量的queue里去;
- 接着临时征用10倍的机器来部署consumer,每一批consumer消费一个临时queue的数据;
- 这种做法相当于是临时将queue资源和consumer资源扩大10倍,以正常的10倍速度来消费数据;
- 等快速消费完积压数据之后,恢复成原来部署。
PS: 如果消息队列是Kafka就更简单了,修改消费类型为latest后执行一次消费然后切换成earliest即可。
追问1:MQ消息过期失效怎么办?
像上面说到的,如果大量积压中的消息过期了,就会被删掉,数据就丢失了。这种其实没有啥好办法,只能等解决积压问题后再处理了。
比如夜深人静,大家都睡觉了,这时积压的消息也吃完了,你揉了揉眼,冲了一杯免费咖啡,找到写好的程序,把过期的数据找回来并重新放到MQ中,让他重新消费一遍就行了。
追问2:如果mq经常写满你会怎么办?
这样如果是消费者这边的硬伤,就只能扩容来搞了,多加一些服务器部署消费者程序。当然,如果可以通过优化程序解决,肯定要选择后者,无论从技术还是业务角度来优化。否则经常写满就意味着经常丢数据,只能人工写程序去补数据,工作量更大,加班更严重,我可不愿意加班。