KubeSphere
编辑
KubeSphere
一、产品介绍
1. 概述
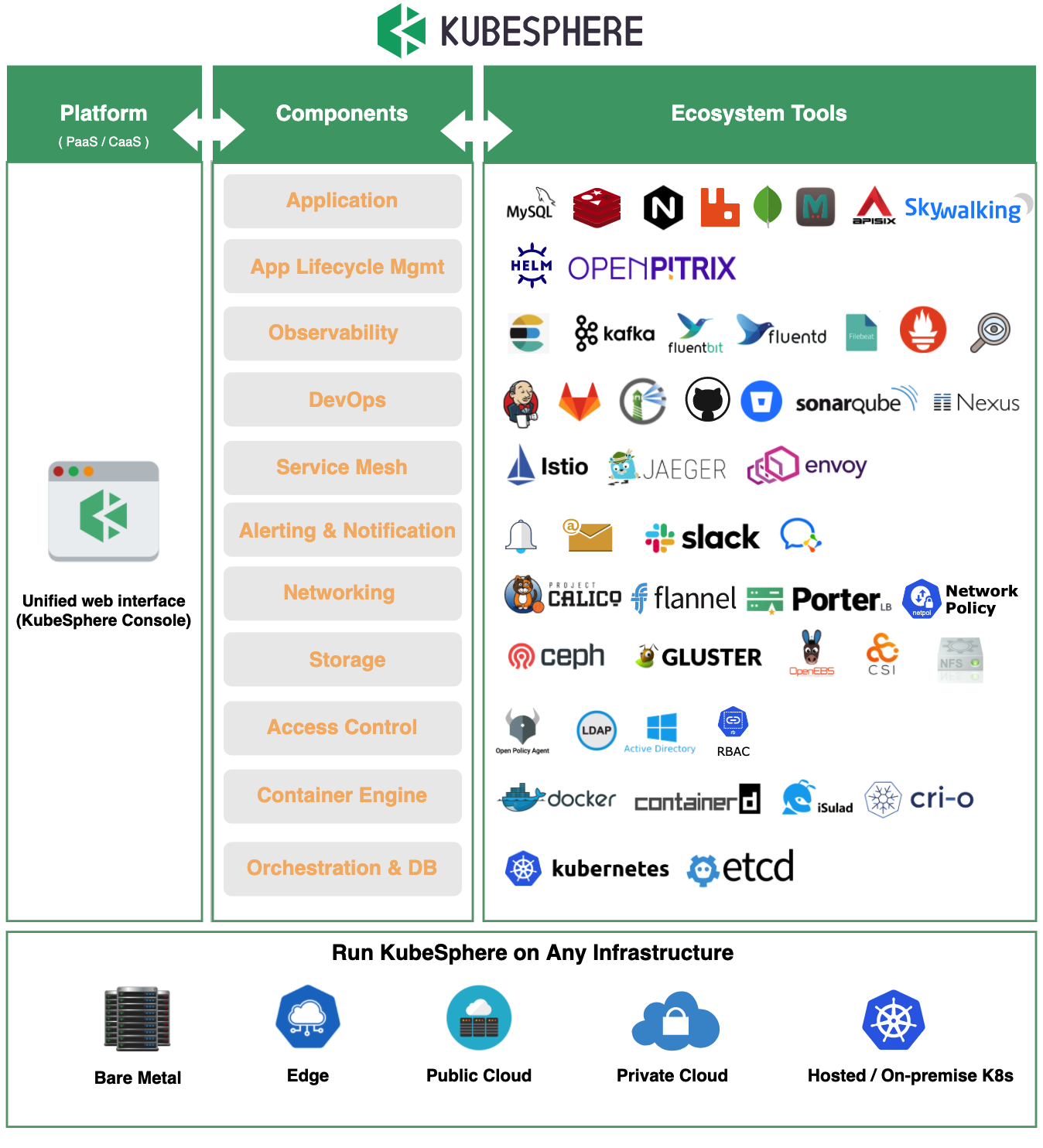
KubeSphere 是在 Kubernetes 之上构建的面向云原生应用的分布式操作系统,完全开源,支持多云与多集群管理,提供全栈的 IT 自动化运维能力,简化企业的 DevOps 工作流。它的架构可以非常方便地使第三方应用与云原生生态组件进行即插即用 (plug-and-play) 的集成。
作为全栈的多租户容器平台,KubeSphere 提供了运维友好的向导式操作界面,帮助企业快速构建一个强大和功能丰富的容器云平台。KubeSphere 为用户提供构建企业级 Kubernetes 环境所需的多项功能,例如多云与多集群管理、Kubernetes 资源管理、DevOps、应用生命周期管理、微服务治理(服务网格)、日志查询与收集、服务与网络、多租户管理、监控告警、事件与审计查询、存储管理、访问权限控制、GPU 支持、网络策略、镜像仓库管理以及安全管理等。
KubeSphere 还开源了 KubeKey 帮助企业一键在公有云或数据中心快速搭建 Kubernetes 集群,提供单节点、多节点、集群插件安装,以及集群升级与运维。

2.丰富的生态工具
KubeSphere 围绕 Kubernetes 集成了多个云原生生态主流的开源软件,同时支持对接大部分流行的第三方组件,从应用和应用生命周期管理到集群底层的运行时,将这些开源项目作为其后端组件,通过标准的 API 与 KubeSphere 控制台交互,最终在一个统一的控制台界面提供一致的用户体验,以降低对不同工具的学习成本和复杂性。
同时,KubeSphere 还具备了 Kubernetes 尚未提供的新功能,旨在解决 Kubernetes 本身存在的存储、网络、安全和易用性等痛点。KubeSphere 不仅允许开发人员和 DevOps 团队在统一的控制台中使用他们喜欢的工具,最重要的是,这些功能与平台松耦合,所有功能组件均支持可插拔安装。
3.平台功能
KubeSphere 作为开源的企业级全栈化容器平台,为用户提供了一个健壮、安全、功能丰富、具备极致体验的 Web 控制台。拥有企业级 Kubernetes 所需的最常见的功能,如工作负载管理,网络策略配置,微服务治理(基于 Istio),DevOps 项目 (CI/CD) ,安全管理,Source to Image/Binary to Image,多租户管理,多维度监控,日志查询和收集,告警通知,审计,应用程序管理和镜像管理、应用配置密钥管理等功能模块。
它还支持各种开源存储和网络解决方案以及云存储服务。例如,KubeSphere 为用户提供了功能强大的云原生工具负载均衡器插件 OpenELB,这是为 Kubernetes 集群开发的 CNCF 认证的负载均衡插件。
有了易于使用的图形化 Web 控制台,KubeSphere 简化了用户的学习曲线并推动了更多的企业使用 Kubernetes 。
3.1 部署和维护 Kubernetes
3.1.1 部署 Kubernetes 集群
KubeKey 允许用户直接在基础架构上部署 Kubernetes,为 Kubernetes 集群提供高可用性。建议在生产环境至少配置三个主节点。
3.1.2 Kubernetes 资源管理
对底层 Kubernetes 中的多种类型的资源提供可视化的展示与监控数据,以向导式 UI 实现工作负载管理、镜像管理、服务与应用路由管理 (服务发现)、密钥配置管理等,并提供弹性伸缩 (HPA) 和容器健康检查支持,支持数万规模的容器资源调度,
保证业务在高峰并发情况下的高可用性。
由于 KubeSphere 3.0 具有增强的可观测性,用户可以从多租户角度跟踪资源,例如自定义监视、事件、审核日志、告警通知。
3.1.3 集群升级和扩展
KubeKey 提供了一种简单的安装,管理和维护方式。它支持 Kubernetes 集群的滚动升级,以便集群服务在升级时始终可用。另外,也可以使用 KubeKey 将新节点添加到 Kubernetes 集群中以使用更多工作负载。
3.2 多集群管理和部署
随着IT界越来越多的企业使用云原生应用程序来重塑软件产品组合,用户更倾向于跨位置、地理位置和云部署集群。在此背景下,KubeSphere 进行了重大升级,以其全新的多集群功能满足用户的迫切需求。
借助 KubeSphere的图形化 Web 控制台,用户可以管理底层的基础架构,例如添加或删除集群。可以使用相同的方式管理部署在任何基础架构(例如 Amazon EKS和Google Kubernetes Engine)上的异构集群。
- 独立:可以在 KubeSphere 容器平台中维护和管理独立部署的 Kubernetes 集群。
- 联邦:多个 Kubernetes 集群可以聚合在一起作为 Kubernetes 资源池。当用户部署应用程序时,副本可以部署在资源池中的不同 Kubernetes 集群上。由此,跨区域和多集群实现了高可用性。
KubeSphere 允许用户跨集群部署应用程序。更重要的是,还可以将应用程序配置为在特定集群上运行。此外,多集群功能与行业领先的应用程序管理平台 OpenPitrix 配合使用,使用户可以在整个生命周期内管理应用程序,包括发行、移除和分发。
3.3 DevOps支持
KubeSphere 提供了基于 Jenkins 的可视化 CI/CD 流水线编辑,无需对 Jenkins 进行配置,同时内置丰富的 CI/CD 流水线插件,包括Binary-to-Image (B2I) 和Source-to-Image (S2I),用于将源代码或二进制文件打包到准备运行的容器映像中。
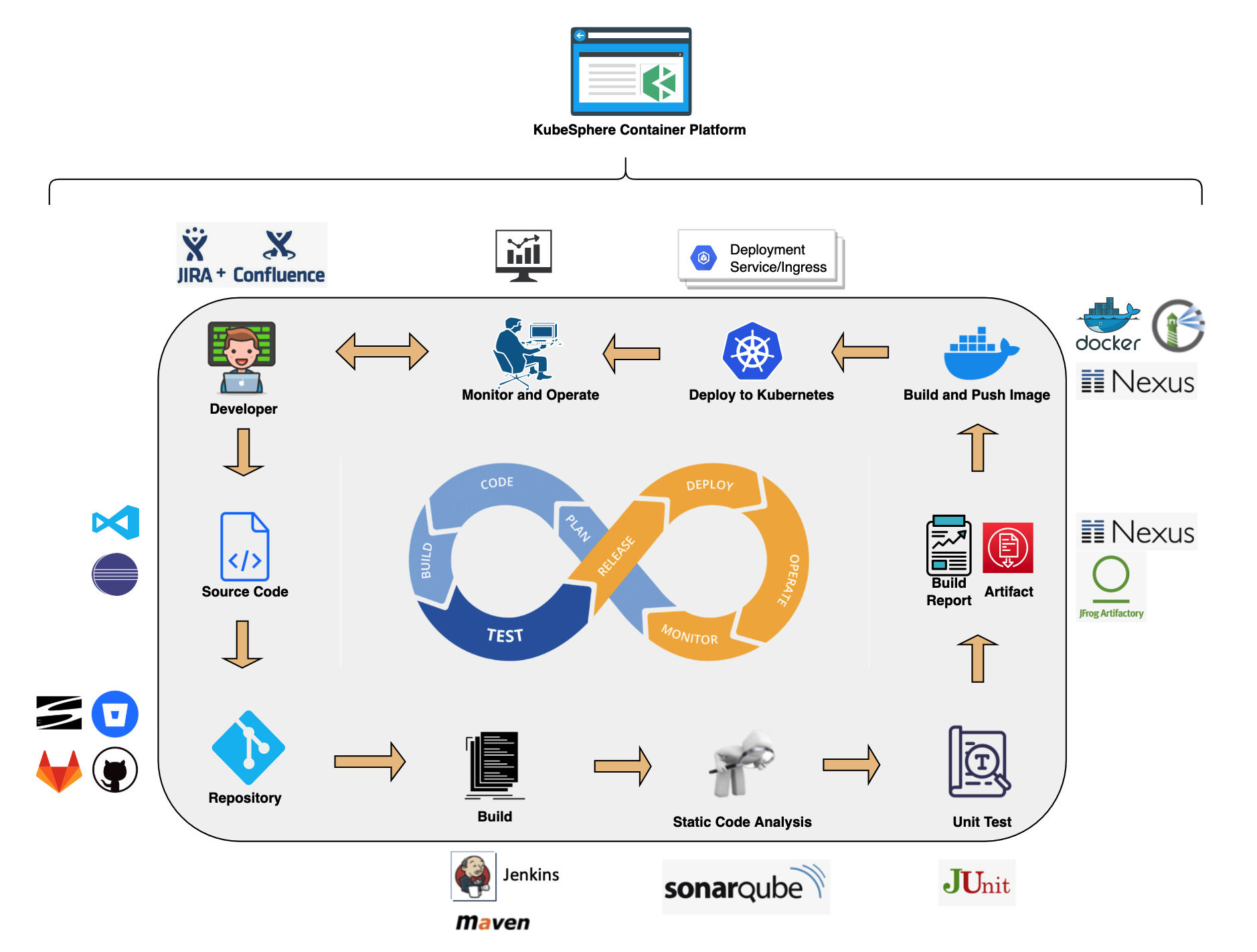
3.3.1 CI/CD 流水线
- 自动化:CI/CD 流水线和构建策略均基于 Jenkins,可简化和自动化开发、测试和生产过程。缓存依赖项用于加速构建和部署。
- 开箱即用:用户可以基于他们的 Jenkins 构建策略和客户端插件来创建基于 Git repository/SVN 的 Jenkins 流水线。在内置的 Jenkinsfile 中定义任何步骤和阶段。支持常见的代理类型,例如 Maven,Node.js 和 Go。用户也可以自定义代理类型。
- 可视化:用户可以轻松地与可视化控制面板进行交互,编辑、管理 CI/CD 流水线。
- 质量管理:支持通过静态代码分析扫描来检测DevOps 项目中的 bug、代码错误和安全漏洞。
- 日志:日志完整记录 CI/CD 流水线运行全过程。
3.3.2 Source-to-Image
Source-to-Image (S2I) 是一个直接将源代码构建成镜像的自动化构建工具,它是通过将源代码放入一个负责编译源代码的构建器镜像(Builder image) 中,自动将编译后的代码打包成 Docker 镜像。
S2I 允许用户将服务发布到 Kubernetes,而无需编写 Dockerfile。只需要提供源代码仓库地址,并指定目标镜像仓库即可。所有配置将在 Kubernetes 中存储为不同的资源。服务将自动发布到 Kubernetes,并且镜像也将推送到目标仓库。
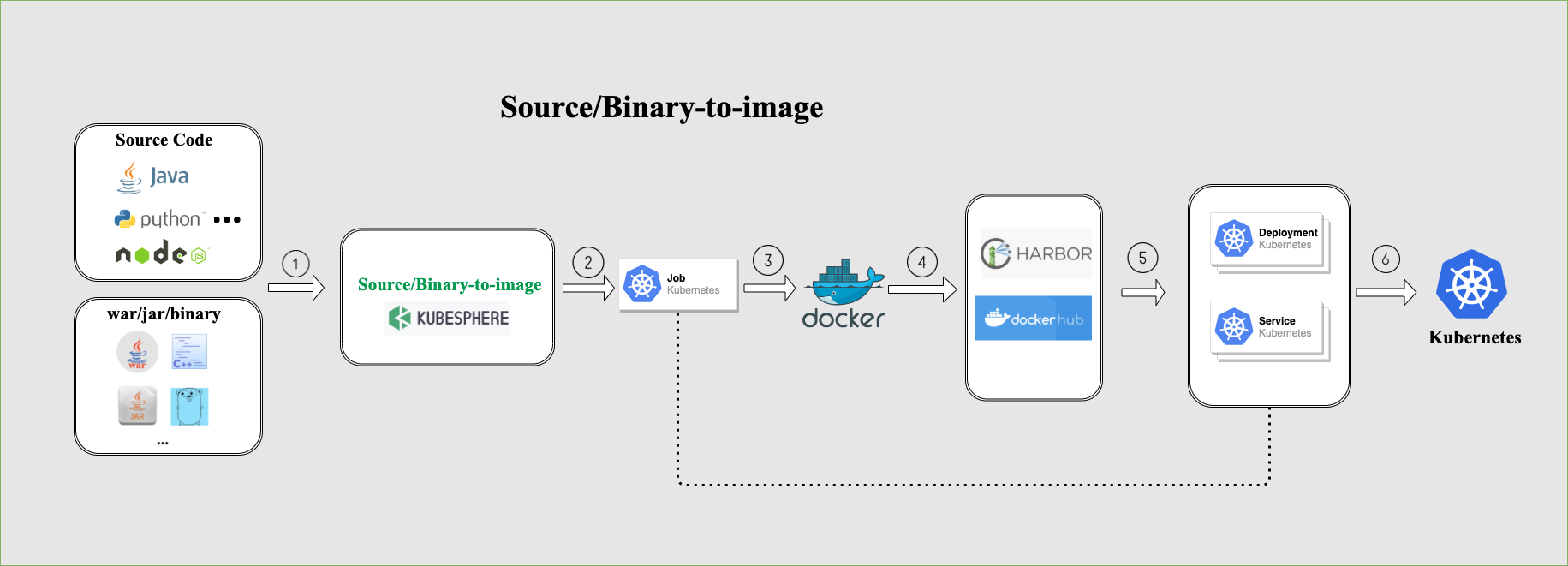
3.3.3 Binary-to-Image
与 S2I 相似,Binary-to-Image (B2I) 是一个直接将二进制文件构建成镜像的自动化构建工具,用于从二进制文件(例如 Jar,War,Binary 包)构建可复制的容器镜像。
用户只需要上传应用程序二进制包,并指定要推送到的镜像仓库即可。其余部分与 S2I 完全相同。
3.4 基于 Istio 的服务网络
KubeSphere 服务网络由一组生态系统项目组成,例如 Istio,Envoy 和 Jaeger。我们设计了一个统一的用户界面来使用和管理这些工具。大多数功能都是现成的,并且是从开发人员的角度进行设计的,这意味着 KubeSphere 可以帮助用户减少学习难度,因为不需要单独深入研究这些工具。
KubeSphere 服务网络为分布式应用程序提供细粒度的流量管理、可观测性、服务跟踪以及服务身份和安全性管理。因此,开发人员只需要专注于核心业务。通过 KubeSphere 的服务网络管理,用户可以更好地跟踪、查看路由和优化 Kubernetes 中用于云原生应用程序的通信。
3.5 流量管理
- 金丝雀发布: 金丝雀发布是在现有生产系统旁边创建了一个全新的独立生产环境,通过使新版本只对少数终端用户可用,这样可降低向推出新代码和功能的风险。如果新版本一切顺利,用户可以更改百分比,并逐渐用新版本替换旧版本。
- 蓝绿发布: 允许用户同时运行一个应用程序的两个版本。蓝色代表当前应用程序版本,绿色代表经过功能和性能测试的新版本。一旦测试结果成功,就将应用程序流量从生产版本(蓝色)路由到新版本(绿色)。
- 流量镜像:流量镜像也叫作影子流量,是指通过一定的配置将线上的真实流量复制一份到镜像服务中去,我们通过流量镜像转发以达到在不影响线上服务的情况下对流量或请求内容做具体分析的目的,它的设计思想是只做转发而不接收响应(fire and forget),使团队能够以最小的风险进行生产变更。
- 断路器: 允许用户设置服务内单个主机的呼叫限制,例如并发连接数或对该主机的呼叫失败次数。
3.6 可视化
KubeSphere 服务网络具有可视化微服务之间的连接以及它们如何互连的拓扑的能力。在这方面,可观测性对于理解云原生微服务的互连非常有帮助。
3.7 分布式跟踪
用户能基于 Jaeger,跟踪 KubeSphere 服务之间的网络交互。它通过可视化帮助用户更深入地了解请求延迟、瓶颈、序列化和并行性。
3.8 多租户管理
在 KubeSphere 中,资源(例如集群)可以在租户之间共享。首先,管理员或运维人员需要使用不同的权限设置不同的帐户角色。可以将这些角色分配给平台中的成员,以对各种资源执行特定的操作。同时,由于 KubeSphere 完全隔离了租户,因此它们根本不会相互影响。
- 多租户:它提供了基于角色的细粒度身份验证和三层授权的系统。
- 统一认证:KubeSphere 与 LDAP 或 AD 协议的中央身份验证系统兼容。还支持单点登录 (SSO),以实现租户身份的统一身份验证。
- 授权系统:它分为三个级别:集群,企业空间和项目。 KubeSphere 确保可以共享资源,同时完全隔离多个级别的不同角色以确保资源安全。
3.9 可观测性
3.9.1 多维度监控
KubeSphere 通过可视化界面操作监控、运维功能,可简化操作和维护的整个过程。它提供了对各种资源的自定义监控,并可以立即将发生的问题发送给用户。
- 可定制的监控仪表板:用户可以准确决定需要以哪种形式监控哪些工具。 KubeSphere 中提供了不同的模板供用户选择,例如 Elasticsearch,MySQL 和 Redis。或者,他们也可以创建自己的监视模板,包括图表,颜色,间隔和单位。
- 运维友好:开放标准接口,易于对接企业运维系统,以统一运维入口实现集中化运维。
- 第三方兼容性:KubeSphere 与 Prometheus 兼容,后者是用于在 Kubernetes 环境中进行监视的事实指标收集平台。监视数据可以在 KubeSphere 的 Web 控制台中无缝显示。
- 二级精度的多维度监控:
- 在集群资源维度,系统提供了全面的指标,例如 CPU 利用率、内存利用率、CPU 平均负载、磁盘使用量、inode 使用率、磁盘吞吐量、IOPS、网卡速率、容器组运行状态、etcd 监控、API Server 监控等多项指标。
- 在应用资源维度,提供针对应用的 CPU 用量、内存用量、容器组数量、网络流出速率、网络流入速率等五项监控指标。并支持按用量排序和自定义时间范围查询,快速定位异常提供按节点、企业空间、项目等资源用量排行。
- 排序:用户可以按节点,工作空间和项目对数据进行排序,从而以直观的方式为他们的资源运行提供图形化视图。
- 组件监控:它允许用户快速定位任何组件故障,以避免不必要的业务停机。
3.9.2 自研多租户告警系统
- 自定义告警策略和规则:支持基于多租户、多维度的监控指标告警。 该系统将发送与各种资源,如节点、网络和工作负载相关的告警。可自定义包含多个告警规则的告警策略,如重复间隔和时间,来定制自己的告警策略、阈值和告警级别。
- 准确的事件跟踪:用户可以及时了解集群内部发生的情况,例如容器运行状态(成功或失败),节点调度和镜像拉取结果。 它们将被准确记录,并在 Web 控制台中显示结果,状态和消息。 在生产环境中,这将帮助用户及时响应任何问题。
- 增强审计安全性:由于 KubeSphere 具有对用户授权的细粒度管理,因此可以将资源和网络完全隔离以确保数据安全。 全面的审核功能使用户可以搜索与任何操作或告警相关的活动。
- 多种通知方式:电子邮件是用户接收相关活动通知并获取所需信息的一种关键方法。用户可以自定义规则来发送邮件,包括自定义发件人电子邮件地址及其收件人列表。此外,KubeSphere 还支持其他渠道,例如 Slack 和微信等。随着后续迭代,KubeSphere 会为用户提供更多的通知渠道和配置。
3.10 日志查询与收集
- 多租户日志管理.:提供多租户日志管理,在 KubeSphere 的日志查询系统中,不同的租户只能看到属于自己的日志信息,支持中文日志检索,支持日志导出。
- 多级日志查询:多级别的日志查询(项目/工作负载/容器组/容器以及关键字)、灵活方便的日志收集配置选项等。
- 多种日志收集平台:用户可以选择多种日志收集平台,例如 Elasticsearch,Kafka 和 Fluentd。
- 落盘日志收集功能:对于将日志以文件形式保存在 Pod 挂盘上的应用,支持开启落盘日志收集功能。
3.11 应用程序管理和编排
- 应用商店:KubeSphere 提供了一个基于开源 OpenPitrix 的应用商店,支持应用上传、应用审核、应用上架与分类、应用部署,为用户提供应用全生命周期管理功能。
- 应用资料库:在 KubeSphere 中,用户可将基于 Helm Chart 模板文件打包好的应用程序包上传并保存在第三方平台之上,例如 QingStor 对象存储服务、AWS S3 或者 GitHub 等,同时在 KubeSphere 控制台上配置并使用这些第三方的应用资料库。
- 应用程式范本:有了应用程序模板,KubeSphere 只需单击一下即可提供一种可视化的方法来部署应用程序。 在内部,应用程序模板可以帮助企业中的不同团队共享中间件和业务系统。 在外部,它们可以用作基于不同方案和需求的应用程序交付的行业标准。
3.12 多种存储解决方案
- 可使用开源存储解决方案,例如 GlusterFS,CephRBD 和 NFS。
- 可使用 NeonSAN CSI 插件连接到 QingStor NeonSAN,以满足低延迟,高弹性和高性能的核心业务要求。
- 可使用 QingCloud CSI 插件连接到 QingCloud 平台中的各种块存储服务。
3.13 多种网络解决方案
- 支持 Calico、Flannel 等开源网络方案。
- OpenELB,是由 KubeSphere 开发团队设计、经过 CNCF 认证的一款适用于物理机部署 Kubernetes 的负载均衡插件。
主要特点:
- ECMP 路由负载均衡
- BGP 动态路由
- VIP 管理
- 分配 Kubernetes 服务中的 LoadBalancerIP (v0.3.0)
- 使用 Helm Chart 安装 (v0.3.0)
- 通过 CRD 动态配置BGP服务器 (v0.3.0)
- 通过 CRD 动态配置BGP对等 (v0.3.0)
4.架构说明
4.1 前后端分离
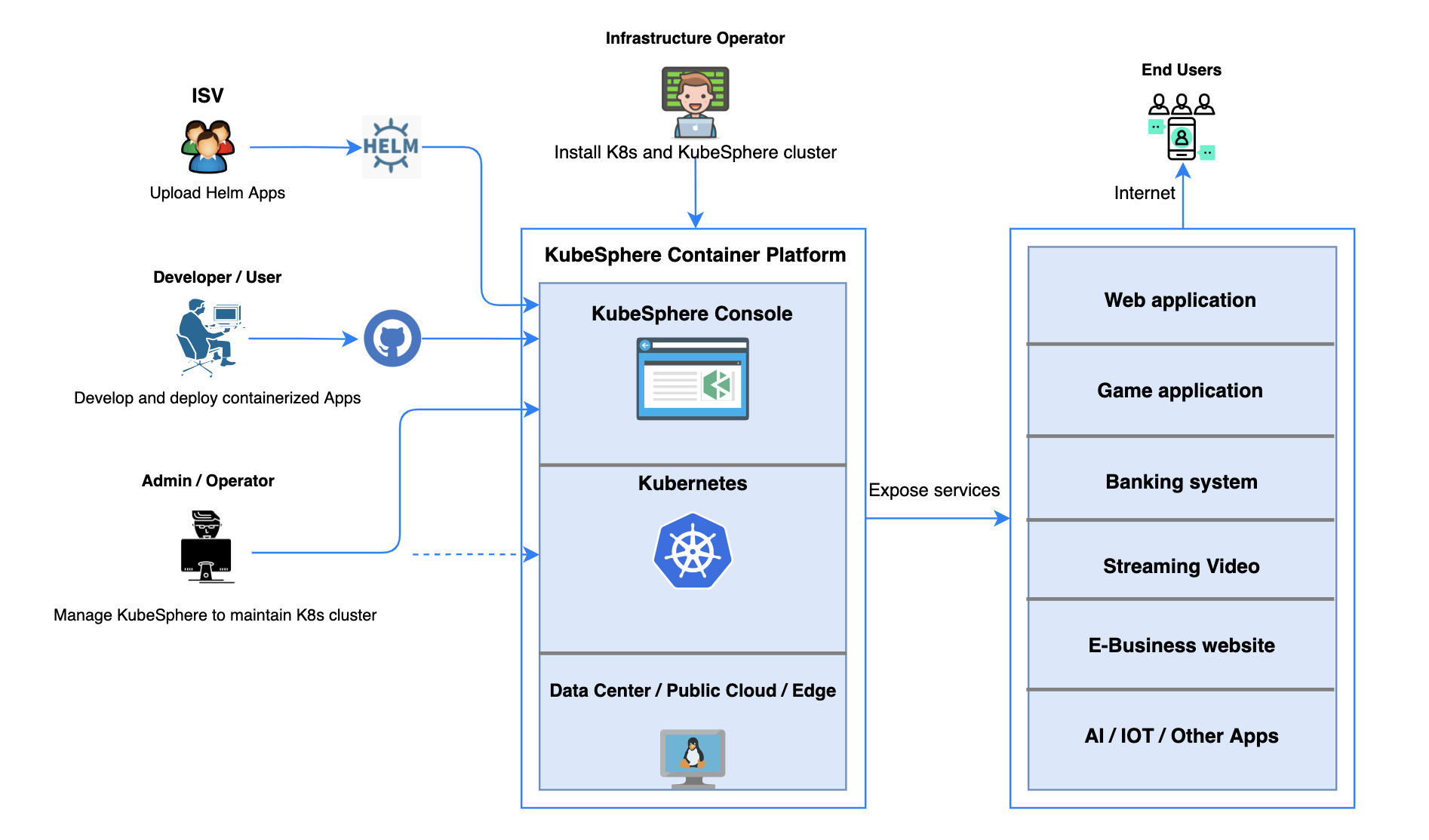
KubeSphere 将 前端 与 后端 分开,实现了面向云原生的设计,后端的各个功能组件可通过 REST API 对接外部系统。 可参考 API文档。下图是系统架构图。 KubeSphere 无底层的基础设施依赖,可以运行在任何 Kubernetes、私有云、公有云、VM 或物理环境(BM)之上。 此外,它可以部署在任何 Kubernetes 发行版上。

4.2 组件列表
| 后端组件 | 功能说明 |
|---|---|
| ks-apiserver | 整个集群管理的 API 接口和集群内部各个模块之间通信的枢纽,以及集群安全控制。 |
| ks-console | 提供 KubeSphere 的控制台服务。 |
| ks-controller-manager | 实现业务逻辑的,例如创建企业空间时,为其创建对应的权限;或创建服务策略时,生成对应的Istio配置等。 |
| metrics-server | Kubernetes 的监控组件,从每个节点的 Kubelet 采集指标信息。 |
| Prometheus | 提供集群,节点,工作负载,API对象的监视指标和服务。 |
| Elasticsearch | 提供集群的日志索引、查询、数据管理等服务,在安装时也可对接您已有的 ES 减少资源消耗。 |
| Fluent Bit | 提供日志接收与转发,可将采集到的⽇志信息发送到 ElasticSearch、Kafka。 |
| Jenkins | 提供 CI/CD 流水线服务。 |
| SonarQube | 可选安装项,提供代码静态检查与质量分析。 |
| Source-to-Image | 将源代码自动将编译并打包成 Docker 镜像,方便快速构建镜像。 |
| Istio | 提供微服务治理与流量管控,如灰度发布、金丝雀发布、熔断、流量镜像等。 |
| Jaeger | 收集 Sidecar 数据,提供分布式 Tracing 服务。 |
| OpenPitrix | 提供应用程序生命周期管理,例如应用模板、应用部署与管理的服务等。 |
| Alert | 提供集群、Workload、Pod、容器级别的自定义告警服务。 |
| Notification | 是一项综合通知服务; 它当前支持邮件传递方法。 |
| Redis | 将 ks-console 与 ks-account 的数据存储在内存中的存储系统。 |
| MySQL | 集群后端组件的数据库,监控、告警、DevOps、OpenPitrix 共用 MySQL 服务。 |
| PostgreSQL | SonarQube 和 Harbor 的后端数据库。 |
| OpenLDAP | 负责集中存储和管理用户帐户信息与对接外部的 LDAP。 |
| Storage | 内置 CSI 插件对接云平台存储服务,可选安装开源的 NFS/Ceph/Gluster 的客户端。 |
| Network | 可选安装 Calico/Flannel 等开源的网络插件,支持对接云平台 SDN。 |
4.3 服务组件
以上列表中每个功能组件下还有多个服务组件。
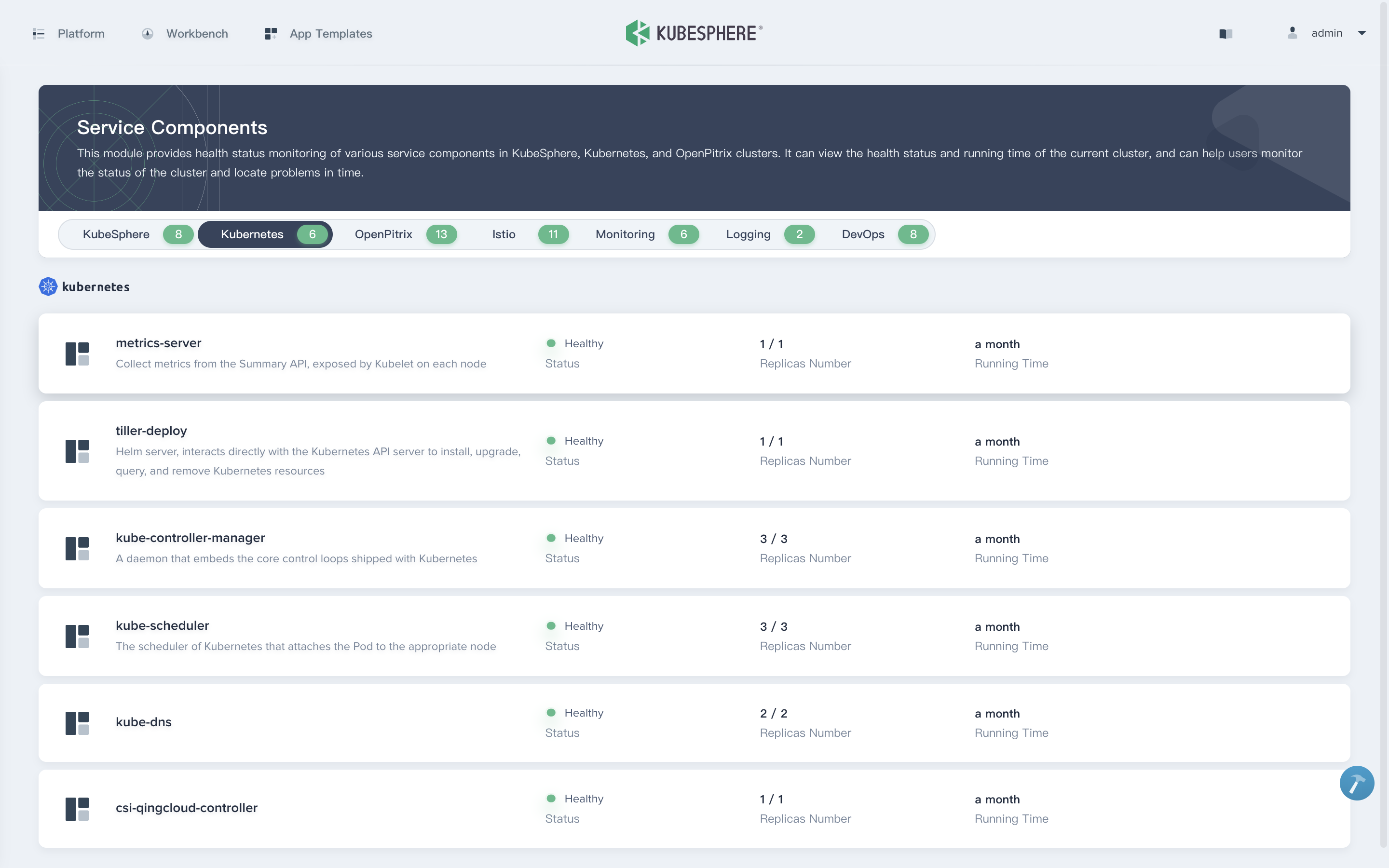
二、快速入门
1.创建企业空间、项目、用户和平台角色
1.1 架构
KubeSphere 的多租户系统分三个层级,即集群、企业空间和项目。KubeSphere 中的项目等同于 Kubernetes 的命名空间。
您需要创建一个新的企业空间进行操作,而不是使用系统企业空间,系统企业空间中运行着系统资源,绝大部分仅供查看。出于安全考虑,强烈建议给不同的租户授予不同的权限在企业空间中进行协作。
您可以在一个 KubeSphere 集群中创建多个企业空间,每个企业空间下可以创建多个项目。KubeSphere 为每个级别默认设有多个内置角色。此外,您还可以创建拥有自定义权限的角色。KubeSphere 多层次结构适用于具有不同团队或组织以及每个团队中需要不同角色的企业用户。
1.2 使用
步骤 1:创建用户
安装 KubeSphere 之后,您需要向平台添加具有不同角色的用户,以便他们可以针对自己授权的资源在不同的层级进行工作。一开始,系统默认只有一个用户 admin,具有 platform-admin 角色。在本步骤中,您将创建一个用户 user-manager,然后使用 user-manager 创建新用户。
1.以 admin 身份使用默认帐户和密码 (admin/P@88w0rd) 登录 Web 控制台。
提示:出于安全考虑,强烈建议您在首次登录控制台时更改密码。若要更改密码,在右上角的下拉列表中选择用户设置,在密码设置中设置新密码,您也可以在用户设置 > 基本信息中修改控制台语言。
2.点击左上角的平台管理,然后选择访问控制。在左侧导航栏中,选择平台角色。四个内置角色的描述信息如下表所示。
| 内置角色 | 描述 |
|---|---|
| workspaces-manager | 企业空间管理员,管理平台所有企业空间。 |
| users-manager | 用户管理员,管理平台所有用户。 |
| platform-regular | 平台普通用户,在被邀请加入企业空间或集群之前没有任何资源操作权限。 |
| platform-admin | 平台管理员,可以管理平台内的所有资源。 |
备注:内置角色由 KubeSphere 自动创建,无法编辑或删除。
3.在用户中,点击创建。在弹出的对话框中,提供所有必要信息(带有*标记),然后在角色一栏选择 users-manager。请参考下图示例。
完成后,点击确定。新创建的帐户将显示在用户中的帐户列表中。
4.切换帐户使用 user-manager 重新登录,创建如下四个新帐户,这些帐户将在其他的教程中使用。
提示: 帐户登出请点击右上角的用户名,然后选择登出。
| 帐户 | 角色 | 描述 |
|---|---|---|
| ws-manager | workspaces-manager | 创建和管理所有企业空间。 |
| ws-admin | platform-regular | 管理指定企业空间中的所有资源(在此示例中,此帐户用于邀请新成员加入该企业空间)。 |
| project-admin | platform-regular | 创建和管理项目以及 DevOps 项目,并邀请新成员加入项目。 |
| project-regular | platform-regular | project-regular 将由 project-admin 邀请至项目或 DevOps 项目。该帐户将用于在指定项目中创建工作负载、流水线和其他资源。 |
5.查看创建的四个帐户。
步骤 2:创建企业空间
在本步骤中,您需要使用上一个步骤中创建的帐户
ws-manager创建一个企业空间。作为管理项目、DevOps 项目和组织成员的基本逻辑单元,企业空间是 KubeSphere 多租户系统的基础。
1.以 ws-manager 身份登录 KubeSphere,它具有管理平台上所有企业空间的权限。点击左上角的平台管理,选择访问控制。在企业空间中,可以看到仅列出了一个默认企业空间 system-workspace,即系统企业空间,其中运行着与系统相关的组件和服务,您无法删除该企业空间。
2.点击右侧的创建,将新企业空间命名为 demo-workspace,并将用户 ws-admin 设置为企业空间管理员。完成后,点击创建。
备注: 如果您已启用
多集群功能,您需要为企业空间分配一个或多个可用集群,以便项目可以在集群中创建。
3.登出控制台,然后以 ws-admin 身份重新登录。在企业空间设置中,选择企业空间成员,然后点击邀请。
4.邀请 project-admin 和 project-regular 进入企业空间,分别授予 workspace-self-provisioner 和 workspace-viewer 角色,点击确定。
备注: 实际角色名称的格式:
<workspace name>-<role name>。例如,在名为demo-workspace的企业空间中,角色 viewer 的实际角色名称为demo-workspace-viewer。
5.将 project-admin 和 project-regular 都添加到企业空间后,点击确定。在企业空间中,您可以看到列出的三名成员。
| 帐户 | 角色 | 描述 |
|---|---|---|
| ws-admin | workspace-admin | 管理指定企业空间中的所有资源(在此示例中,此帐户用于邀请新成员加入企业空间)。 |
| project-admin | workspace-self-provisioner | 创建和管理项目以及 DevOps 项目,并邀请新成员加入项目。 |
| project-regular | workspace-viewer | project-regular 将由 project-admin 邀请至项目或 DevOps 项目。该帐户将用于在指定项目中创建工作负载、流水线和其他资源。 |
步骤 3:创建项目
在此步骤中,您需要使用在上一步骤中创建的帐户 project-admin 来创建项目。KubeSphere 中的项目与 Kubernetes 中的命名空间相同,为资源提供了虚拟隔离。有关更多信息,请参见命名空间。
1.以 project-admin 身份登录 KubeSphere Web 控制台,在项目中,点击创建。
2.输入项目名称(例如 demo-project),然后点击确定完成,您还可以为项目添加别名和描述。
3.在项目中,点击刚创建的项目查看其详情页面。
4.在项目的概览页面,默认情况下未设置项目配额。您可以点击编辑配额并根据需要指定资源请求和限制(例如:CPU 和内存的限制分别设为 1 Core 和 1000 Gi)。
5.在项目设置 > 项目成员中,邀请 project-regular 至该项目,并授予该用户 operator 角色。
信息: 具有 operator 角色的用户是项目维护者,可以管理项目中除用户和角色以外的资源。
6.在创建应用路由(即 Kubernetes 中的 Ingress)之前,需要启用该项目的网关。网关是在项目中运行的 NGINX Ingress 控制器。若要设置网关,请转到项目设置中的网关设置,然后点击设置网关。此步骤中仍使用帐户 project-admin。
7.选择访问方式 NodePort,然后点击确定。
8.在网关设置下,可以在页面上看到网关地址以及 http/https 的端口。
备注: 如果要使用
LoadBalancer暴露服务,则需要使用云厂商的 LoadBalancer 插件。如果您的 Kubernetes 集群在裸机环境中运行,建议使用OpenELB作为 LoadBalancer 插件。
步骤 4:创建角色
完成上述步骤后,您已了解可以为不同级别的用户授予不同角色。先前步骤中使用的角色都是 KubeSphere 提供的内置角色。在此步骤中,您将学习如何创建自定义角色以满足工作需求。
1.再次以 admin 身份登录 KubeSphere Web 控制台,转到访问控制。
2.点击左侧导航栏中的平台角色,再点击右侧的创建。
备注: 平台角色页面的预设角色无法编辑或删除。
3.在创建平台角色对话框中,设置角色标识符(例如,clusters-admin)、角色名称和描述信息,然后点击编辑权限。
备注: 本示例演示如何创建负责集群管理的角色。
4.在编辑权限对话框中,设置角色权限(例如,选择集群管理)并点击确定。
备注:
5.在平台角色页面,可以点击所创建角色的名称查看角色详情,点击 以编辑角色、编辑角色权限或删除该角色。
6.在用户页面,可以在创建帐户或编辑现有帐户时为帐户分配该角色。
步骤 5:创建 DevOps 项目(可选)
备注: 若要创建 DevOps 项目,需要预先启用 KubeSphere DevOps 系统,该系统是个可插拔的组件,提供 CI/CD 流水线、Binary-to-Image 和 Source-to-Image 等功能。有关如何启用 DevOps 的更多信息,请参见 KubeSphere DevOps 系统。
1.以 project-admin 身份登录控制台,在 DevOps 项目中,点击创建。
2.输入 DevOps 项目名称(例如 demo-devops),然后点击确定,也可以为该项目添加别名和描述。
3.点击刚创建的项目查看其详细页面。
4.转到 DevOps 项目设置,然后选择 DevOps 项目成员。点击邀请授予 project-regular 用户 operator 的角色,允许其创建流水线和凭证。
三、多集群管理
资源要求
| 命名空间 | kube-federation-system | kubesphere-system |
|---|---|---|
| 子组件 | 2 x controller-manager | Tower |
| CPU 请求 | 100 m | 100 m |
| CPU 限制 | 500 m | 500 m |
| 内存请求 | 64 MiB | 128 MiB |
| 内存限制 | 512 MiB | 256 MiB |
| 安装 | 可选 | 可选 |
备注 CPU 和内存的资源请求和限制均指单个副本的要求。 多集群功能启用后,主集群上会安装 Tower 和 controller-manager。如果您使用代理连接,成员集群仅需要 Tower。如果您使用直接连接,成员集群无需额外组件。
在多集群架构中使用应用商店
与 KubeSphere 中的其他组件不同,KubeSphere 应用商店是所有集群(包括主集群和成员集群)的全局应用程序池。您只需要在主集群上启用应用商店,便可以直接在成员集群上使用应用商店的相关功能(无论成员集群是否启用应用商店),例如应用模板和应用仓库。
但是,如果只在成员集群上启用应用商店而没有在主集群上启用,您将无法在多集群架构中的任何集群上使用应用商店。
直接连接
如果主集群的任何节点都能访问的 kube-apiserver 地址,您可以采用直接连接。当成员集群的 kube-apiserver 地址可以暴露给外网,或者主集群和成员集群在同一私有网络或子网中时,此方法均适用。
要通过直接连接使用多集群功能,您必须拥有至少两个集群,分别用作主集群和成员集群。您可以在安装 KubeSphere 之前或者之后将一个集群指定为主集群或成员集群。有关安装 KubeSphere 的更多信息,请参考在 Linux 上安装和在 Kubernetes 上安装。
准备主集群
主集群为您提供中央控制平面,并且您只能指定一个主集群。
已经安装 KubeSphere
如果已经安装了独立的 KubeSphere 集群,您可以编辑集群配置,将 clusterRole 的值设置为 host。
- 选项 A - 使用 Web 控制台:
使用 admin 帐户登录控制台,然后进入集群管理页面上的 CRD,输入关键字 ClusterConfiguration,然后转到其详情页面。编辑 ks-installer 的 YAML 文件,方法类似于启用可插拔组件。
- 选项 B - 使用 Kubectl:
kubectl edit cc ks-installer -n kubesphere-system
在 ks-installer 的 YAML 文件中,搜寻到 multicluster,将 clusterRole 的值设置为 host,然后点击确定(如果使用 Web 控制台)使其生效:
multicluster:
clusterRole: host
要设置主集群名称,请在 ks-installer 的 YAML 文件中的 multicluster.clusterRole 下添加 hostClusterName 字段:
multicluster:
clusterRole: host
hostClusterName: <主集群名称>
备注 * 建议您在准备主集群的同时设置主集群名称。若您的主集群已在运行并且已经部署过资源,不建议您再去设置主集群名称。 * 主集群名称只能包含小写字母、数字、连字符(-)或者半角句号(.),必须以小写字母或数字开头和结尾。
您需要稍等片刻待该更改生效。
您可以使用 kubectl 来获取安装日志以验证状态。运行以下命令,稍等片刻,如果主集群已准备就绪,您将看到成功的日志返回。
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
准备成员集群
为了通过主集群管理,您需要使它们之间的 jwtSecret 相同。因此,您首先需要在主集群中执行以下命令来获取它。
kubectl -n kubesphere-system get cm kubesphere-config -o yaml | grep -v "apiVersion" | grep jwtSecret
命令输出结果可能如下所示:
jwtSecret: "gfIwilcc0WjNGKJ5DLeksf2JKfcLgTZU"
已经安装 KubeSphere
如果已经安装了独立的 KubeSphere 集群,您可以编辑集群配置,将 clusterRole 的值设置为 member。
- 选项 A - 使用 Web 控制台:
使用 admin 帐户登录控制台,然后进入集群管理页面上的 CRD,输入关键字 ClusterConfiguration,然后转到其详情页面。编辑 ks-installer 的 YAML 文件,方法类似于启用可插拔组件。
- 选项 B - 使用 Kubectl:
kubectl edit cc ks-installer -n kubesphere-system
在 ks-installer 的 YAML 文件中对应输入上面所示的 jwtSecret:
authentication:
jwtSecret: gfIwilcc0WjNGKJ5DLeksf2JKfcLgTZU
向下滚动并将 clusterRole 的值设置为 member,然后点击确定(如果使用 Web 控制台)使其生效:
multicluster:
clusterRole: member
您需要稍等片刻待该更改生效。
您可以使用 kubectl 来获取安装日志以验证状态。运行以下命令,稍等片刻,如果已准备就绪,您将看到成功的日志返回。
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
导入成员集群
- 以 admin 身份登录 KubeSphere 控制台,转到集群管理页面点击添加集群。
- 在导入集群页面,输入要导入的集群的基本信息。您也可以点击右上角的编辑模式以 YAML 格式查看并编辑基本信息。编辑完成后,点击下一步。
- 在连接方式,选择直接连接 Kubernetes 集群,复制 kubeconfig 内容并粘贴至文本框。您也可以点击右上角的编辑模式以 YAML 格式编辑的 kubeconfig。
- 点击创建,然后等待集群初始化完成。
备注: 请确保主集群的任何节点都能访问 kubeconfig 中的 server 地址。
代理连接
KubeSphere 的组件 Tower 用于代理连接。Tower 是一种通过代理在集群间建立网络连接的工具。如果主集群无法直接访问成员集群,您可以暴露主集群的代理服务地址,这样可以让成员集群通过代理连接到主集群。当成员集群部署在私有环境(例如 IDC)并且主集群可以暴露代理服务时,适用此连接方法。当您的集群分布部署在不同的云厂商上时,同样适用代理连接的方法。
要通过代理连接使用多集群功能,您必须拥有至少两个集群,分别用作主集群和成员集群。您可以在安装 KubeSphere 之前或者之后将一个集群指定为主集群或成员集群。有关安装 KubeSphere 的更多信息,请参考在 Linux 上安装和在 Kubernetes 上安装。
准备主集群
主集群为您提供中央控制平面,并且您只能指定一个主集群。
已经安装 KubeSphere
如果已经安装了独立的 KubeSphere 集群,您可以编辑集群配置,将 clusterRole 的值设置为 host。
- 选项 A - 使用 Web 控制台:
使用 admin 帐户登录控制台,然后进入集群管理页面上的 CRD,输入关键字 ClusterConfiguration,然后转到其详情页面。编辑 ks-installer 的 YAML 文件,方法类似于启用可插拔组件。
- 选项 B - 使用 Kubectl:
kubectl edit cc ks-installer -n kubesphere-system
在 ks-installer 的 YAML 文件中,搜寻到 multicluster,将 clusterRole 的值设置为 host,然后点击确定(如果使用 Web 控制台)使其生效:
multicluster:
clusterRole: host
要设置主集群名称,请在 ks-installer 的 YAML 文件中的 multicluster.clusterRole 下添加 hostClusterName 字段:
multicluster:
clusterRole: host
hostClusterName: <主集群名称>
备注 建议您在准备主集群的同时设置主集群名称。若您的主集群已在运行并且已经部署过资源,不建议您再去设置主集群名称。 主集群名称只能包含小写字母、数字、连字符(-)或者半角句号(.),必须以小写字母或数字开头和结尾。
您需要稍等片刻待该更改生效。
您可以使用 kubectl 来获取安装日志以验证状态。运行以下命令,稍等片刻,如果主集群已准备就绪,您将看到成功的日志返回。
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
设置代理服务地址
安装主集群后,将在 kubesphere-system 中创建一个名为 tower 的代理服务,其类型为 LoadBalancer。
集群中有可用的 LoadBalancer
如果集群中有可用的 LoadBalancer 插件,则可以看到 Tower 服务有相应的 EXTERNAL-IP 地址,该地址将由 KubeSphere 自动获取并配置代理服务地址,这意味着您可以跳过设置代理服务地址这一步。执行以下命令确认是否有 LoadBalancer 插件。
kubectl -n kubesphere-system get svc
命令输出结果可能如下所示:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tower LoadBalancer 10.233.63.191 139.198.110.23 8080:30721/TCP 16h
备注 一般来说,主流公有云厂商会提供 LoadBalancer 解决方案,并且负载均衡器可以自动分配外部 IP。如果您的集群运行在本地环境中,尤其是在裸机环境中,可以使用 OpenELB 作为负载均衡器解决方案。
准备成员集群
为了通过主集群管理成员集群,您需要使它们之间的 jwtSecret 相同。因此,您首先需要在主集群中执行以下命令来获取它。
kubectl -n kubesphere-system get cm kubesphere-config -o yaml | grep -v "apiVersion" | grep jwtSecret
命令输出结果可能如下所示:
jwtSecret: "gfIwilcc0WjNGKJ5DLeksf2JKfcLgTZU"
已经安装 KubeSphere
如果已经安装了独立的 KubeSphere 集群,您可以编辑集群配置,将 clusterRole 的值设置为 member。
- 选项 A - 使用 Web 控制台:
使用 admin 帐户登录控制台,然后进入集群管理页面上的 CRD,输入关键字 ClusterConfiguration,然后转到其详情页面。编辑 ks-installer 的 YAML 文件,方法类似于启用可插拔组件。
- 选项 B - 使用 Kubectl:
kubectl edit cc ks-installer -n kubesphere-system
在 ks-installer 的 YAML 文件中对应输入上面所示的 jwtSecret:
authentication:
jwtSecret: gfIwilcc0WjNGKJ5DLeksf2JKfcLgTZU
向下滚动并将 clusterRole 的值设置为 member,然后点击确定(如果使用 Web 控制台)使其生效:
multicluster:
clusterRole: member
您需要稍等片刻待该更改生效。
您可以使用 kubectl 来获取安装日志以验证状态。运行以下命令,稍等片刻,如果成员集群已准备就绪,您将看到成功的日志返回。
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
导入成员集群
- 以 admin 身份登录 KubeSphere 控制台,转到集群管理页面点击添加集群。
- 在导入集群页面输入要导入的集群的基本信息。您也可以点击右上角的编辑模式以 YAML 格式查看并编辑基本信息。编辑完成后,点击下一步。
- 在连接方式,选择集群连接代理,然后点击创建。主集群为代理部署 (Deployment) 生成的 YAML 配置文件会显示在控制台上。
- 根据指示在成员集群中创建一个 agent.yaml 文件,然后将代理部署复制并粘贴到该文件中。在该节点上执行 kubectl create -f agent.yaml 然后等待代理启动并运行。请确保成员集群可以访问代理地址。
- 待集群代理启动并运行,您会看到成员集群已经导入主集群。
获取 Kubeconfig
如果您使用直接连接导入,则需要提供 kubeconfig。
准备工作
您有一个 Kubernetes 集群。
获取 Kubeconfig
进入 $HOME/.kube,检查目录中的文件,通常该目录下存在一个名为 config 的文件。使用以下命令获取 kubeconfig 文件:
cat $HOME/.kube/config
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUN5RENDQWJDZ0F3SUJBZ0lCQURBTkJna3Foa2lHOXcwQkFRc0ZBREFWTVJNd0VRWURWUVFERXdwcmRXSmwKY201bGRHVnpNQjRYRFRJd01EZ3dPREE1hqaVE3NXhwbGFQNUgwSm5ySk5peTBacFh6QWxjYzZlV2JlaXJ1VgpUbmZUVjZRY3pxaVcrS3RBdFZVbkl4MCs2VTgzL3FiKzdINHk2RnA0aVhUaDJxRHJ6Qkd4dG1UeFlGdC9OaFZlCmhqMHhEbHVMOTVUWkRjOUNmSFgzdGZJeVh5WFR3eWpnQ2g1RldxbGwxVS9qVUo2RjBLVVExZ1pRTFp4TVJMV0MKREM2ZFhvUGlnQ3BNaVRPVXl5SVNhWUVjYVNBMEo5VWZmSGd4ditVcXVleTc0cEM2emszS0lOT2tGMkI1MllxeApUa09OT2VkV2hDUExMZkUveVJqeGw1aFhPL1Z4REFaVC9HQ1Y1a0JZN0toNmRhendmUllOa21IQkhDMD0KLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo=hqaVE3NXhwbGFQNUgwSm5ySk5peTBacFh6QWxjYzZlV2JlaXJ1VgpUbmZUVjZRY3pxaVcrS3RBdFZVbkl4MCs2VTgzL3FiKzdINHk2RnA0aVhUaDJxRHJ6Qkd4dG1UeFlGdC9OaFZlCmhqMHhEbHVMOTVUWkRjOUNmSFgzdGZJeVh5WFR3eWpnQ2g1RldxbGwxVS9qVUo2RjBLVVExZ1pRTFp4TVJMV0MKREM2ZFhvUGlnQ3BNaVRPVXl5SVNhWUVjYVNBMEo5VWZmSGd4ditVcXVleTc0cEM2emszS0lOT2tGMkI1MllxeApUa09OT2VkV2hDUExMZkUveVJqeGw1aFhPL1Z4REFaVC9HQ1Y1a0JZN0toNmRhendmUllOa21IQkhDMD0KLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo=
server: https://lb.kubesphere.local:6443
name: cluster.local
contexts:
- context:
cluster: cluster.local
user: kubernetes-admin
name: kubernetes-admin@cluster.local
current-context: kubernetes-admin@cluster.local
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUM4akNDQWRxZ0F3SUJBZ0lJRzd5REpscVdjdTh3RFFZSktvWklodmNOQVFFTEJRQXdGVEVUTUJFR0ExVUUKQXhNS2EzVmlaWEp1WlhSbGN6QWVGdzB5TURBNE1EZ3dPVEkzTXpkYUZ3MHlNVEE0TURnd09USTNNemhhTURReApGekFWQmdOVkJBb1REbk41YzNSbGJUcHRZWE4wWlhKek1Sa3dGd1lEVlFRREV4QnsOTJBUkJDNTRSR3BsZ3VmCmw5a0hPd0lEQVFBQm95Y3dKVEFPQmdOVkhROEJBZjhFQkFNQ0JhQXdFd1lEVlIwbEJBd3dDZ1lJS3dZQkJRVUgKQXdJd0RRWUpLb1pJaHZjTkFRRUxCUUFEZ2dFQkFEQ2FUTXNBR1Vhdnhrazg0NDZnOGNRQUJpSmk5RTZiREV5TwphRnJubC8reGRzRmgvOTFiMlNpM3ZwaHFkZ2k5bXRYWkhhaWI5dnQ3aXdtSEFwbGQxUkhBU25sMFoxWFh1dkhzCmMzcXVIU0puY3dmc3JKT0I4UG9NRjVnaG10a0dPV3g0M2RHTTNHQnpGTVJ4ZGcrNmttNjRNUGhneXl6NTJjYUoKbzhPajNja1Uzd1NWNkxvempRcFVaUnZHV25qQjEwUXFPWXBtQUk4VCtlZkxKZzhuY0drK3V3UUVTeXBYWExpYwoxWVQ2QkFJeFhEK2tUUU1hOFhjdUhHZzlWRkdsUm9yK1EvY3l0S3RDeHVncFlxQ2xvbHVpckFUUnpsemRXamxYCkVQaHVjRWs2UUdIZEpObjd0M2NwRGkzSUdYYXJFdGxQQmFwck9nSGpkOHZVOStpWXdoQT0KLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo=TJBUkJDNTRSR3BsZ3VmCmw5a0hPd0lEQVFBQm95Y3dKVEFPQmdOVkhROEJBZjhFQkFNQ0JhQXdFd1lEVlIwbEJBd3dDZ1lJS3dZQkJRVUgKQXdJd0RRWUpLb1pJaHZjTkFRRUxCUUFEZ2dFQkFEQ2FUTXNBR1Vhdnhrazg0NDZnOGNRQUJpSmk5RTZiREV5TwphRnJubC8reGRzRmgvOTFiMlNpM3ZwaHFkZ2k5bXRYWkhhaWI5dnQ3aXdtSEFwbGQxUkhBU25sMFoxWFh1dkhzCmMzcXVIU0puY3dmc3JKT0I4UG9NRjVnaG10a0dPV3g0M2RHTTNHQnpGTVJ4ZGcrNmttNjRNUGhneXl6NTJjYUoKbzhPajNja1Uzd1NWNkxvempRcFVaUnZHV25qQjEwUXFPWXBtQUk4VCtlZkxKZzhuY0drK3V3UUVTeXBYWExpYwoxWVQ2QkFJeFhEK2tUUU1hOFhjdUhHZzlWRkdsUm9yK1EvY3l0S3RDeHVncFlxQ2xvbHVpckFUUnpsemRXamxYCkVQaHVjRWs2UUdIZEpObjd0M2NwRGkzSUdYYXJFdGxQQmFwck9nSGpkOHZVOStpWXdoQT0KLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo=
client-key-data: LS0tLS1CRUdJTiBSU0EgUFJJVkFURSBLRVktLS0tLQpNSUlFcEFJQkFBS0NBUUVBeXBLWkdtdmdiSHdNaU9pVU80UHZKZXB2MTJaaE1yRUIxK2xlVnM0dHIzMFNGQ0p1Ck8wc09jL2lUNmFuWEJzUU1XNDF6V3hwV1B5elkzWXlUWEJMTlIrM01pWTl2SFhUeWJ6eitTWnNlTzVENytHL3MKQnR5NkovNGpJb2pZZlRZNTFzUUxyRVJydStmVnNGeUU0U2dXbE1HYWdqV0RIMFltM0VJsOTJBUkJDNTRSR3BsZ3VmCmw5a0hPd0lEQVFBQm95Y3dKVEFPQmdOVkhROEJBZjhFQkFNQ0JhQXdFd1lEVlIwbEJBd3dDZ1lJS3dZQkJRVUgKQXdJd0RRWUpLb1pJaHZjTkFRRUxCUUFEZ2dFQkFEQ2FUTXNBR1Vhdnhrazg0NDZnOGNRQUJpSmk5RTZiREV5TwphRnJubC8reGRzRmgvOTFiMlNpM3ZwaHFkZ2k5bXRYWkhhaWI5dnQ3aXdtSEFwbGQxUkhBU25sMFoxWFh1dkhzCmMzcXVIU0puY3dmc3JKT0I4UG9NRjVnaG10a0dPV3g0M2RHTTNHQnpGTVJ4ZGcrNmttNjRNUGhneXl6NTJjYUoKbzhPajNja1Uzd1NWNkxvempRcFVaUnZHV25qQjEwUXFPWXBtQUk4VCtlZkxKZzhuY0drK3V3UUVTeXBYWExpYwoxWVQ2QkFJeFhEK2tUUU1hOFhjdUhHZzlWRkdsUm9yK1EvY3l0S3RDeHVncFlxQ2xvbHVpckFUUnpsemRXamxYCkVQaHVjRWs2UUdIZEpObjd0M2NwRGkzSUdYYXJFdGxQQmFwck9nSGpkOHZVOStpWXdoQT0KLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo=Ygo3THE3a2tBMURKNTBld2pMUTNTd1Yxd2p6N2ZjeDYvbzUwRnJnK083dEJMVVdQNTNHaDQ1VjJpUEp2NkdPYk1uCjhIWElmem83cW5XRFQvU20ybW5HbitUdVY4THdLVWFXL2wya3FkRUNnWUVBcS9zRmR1RDk2Z3VoT2ZaRnczcWMKblZGekNGQ3JsMkUvVkdYQy92SmV1WnJLQnFtSUtNZFI3ajdLWS9WRFVlMnJocVd6MFh2Wm9Sa1FoMkdwWkdIawpDd3NzcENKTVl4L0hETTVaWlBvcittb1J6VE5HNHlDNGhTRGJ2VEFaTmV1VTZTK1hzL1JSTDJ6WnUwemNQQXk1CjJJRVgwelFpZ1JzK3VzS3Jkc1FVZXZrQ2dZQUUrQUNWeDJnMC94bmFsMVFJNmJsK3Y2TDJrZVJtVGppcHB4Wm0KS1JEd2xnaXpsWGxsTjhyQmZwSGNiK1ZnZ282anN2eHFrb0pkTEhBLzFDME5IMWVuS1NoUTlpZVFpeWNsZngwdQpKOE1oeW1JM0RBZUg1REJyOG1rZ0pwNnJwUXNBc1paYmVhOHlLTzV5eVdCYTN6VGxOVnQvNDRibGg5alpnTWNMCjNyUXFVUUtCZ1FETVlXdEt2S0hOQllXV0p5enFERnFPbS9qY3Z3andvcURibUZVMlU3UGs2aUdNVldBV3VYZ3cKSm5qQWtES01GN0JXSnJRUjR6RHVoQlhvQVMxWVhiQ2lGd2hTcXVjWGhFSGlwQ3Nib0haVVRtT1pXUUh4Vlp4bQowU1NiRXFZU2MvZHBDZ1BHRk9IaW1FdUVic05kc2JjRmRETDQyODZHb0psQUxCOGc3VWRUZUE9PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=
解绑集群
本教程演示如何将集群与 KubeSphere 的中央控制平面解绑。
准备工作
- 您已经启用多集群管理。
- 您需要有一个拥有集群管理权限角色的用户。例如,您可以直接以 admin 身份登录控制台,或者创建一个拥有该权限的新角色并授予至一个用户。
解绑集群
- 点击左上角的平台管理,然后选择集群管理。
- 在集群管理页面,请点击要从中央控制平面移除的集群。
- 在集群设置下的基本信息页面,请选择我已了解操作所带来的风险,然后点击解绑。
备注 解绑集群后,您将无法在中央控制平面管理该集群,但该集群上的 Kubernetes 资源不会被删除。
解绑不健康的集群
在某些情况下,您无法按照上述步骤解绑集群。例如,您导入了一个凭证错误的集群,并且无法访问集群设置。在这种情况下,请执行以下命令来解绑不健康的集群:
kubectl delete cluster <cluster name>
四、启动组件
KubeSphere 应用商店
作为一个开源的、以应用为中心的容器平台,KubeSphere 在 OpenPitrix 的基础上,为用户提供了一个基于 Helm 的应用商店,用于应用生命周期管理。OpenPitrix 是一个开源的 Web 平台,用于打包、部署和管理不同类型的应用。KubeSphere 应用商店让 ISV、开发者和用户能够在一站式服务中只需点击几下就可以上传、测试、安装和发布应用。
对内,KubeSphere 应用商店可以作为不同团队共享数据、中间件和办公应用的场所。对外,有利于设立构建和交付的行业标准。启用该功能后,您可以通过应用模板添加更多应用。
在安装前启用应用商店
在 Linux 上安装
当您在 Linux 上安装多节点 KubeSphere 时,首先需要创建一个配置文件,该文件列出了所有 KubeSphere 组件。
- 在 Linux 上安装 KubeSphere 时,您需要创建一个默认文件
config-sample.yaml,通过执行以下命令修改该文件:
vi config-sample.yaml
备注 如果您采用 All-in-One 安装,则不需要创建 `config-sample.yaml` 文件,因为可以直接创建集群。一般来说,All-in-One 模式是为那些刚接触 KubeSphere 并希望熟悉系统的用户而准备的。如果您想在这个模式下启用应用商店(比如用于测试),请参考下面的部分,查看如何在安装后启用应用商店。
- 在该文件中,搜索
openpitrix,并将enabled的false改为true,完成后保存文件。
openpitrix:
store:
enabled: true # 将“false”更改为“true”。
- 执行以下命令使用该配置文件创建集群:
./kk create cluster -f config-sample.yaml
在 Kubernetes 上安装
当您在 Kubernetes 上安装 KubeSphere 时,需要先在 cluster-configuration.yaml 文件中启用应用商店。
- 下载
cluster-configuration.yaml文件,执行以下命令打开并编辑该文件。
vi cluster-configuration.yaml
- 在
cluster-configuration.yaml文件中,搜索openpitrix,并将enabled的false改为true。完成后保存文件。
openpitrix:
store:
enabled: true # 将“false”更改为“true”。
- 执行以下命令开始安装:
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
在安装后启用应用商店
- 使用 admin 用户登录控制台,点击左上角的平台管理,选择集群管理。
- 点击 CRD,在搜索栏中输入
clusterconfiguration,点击结果查看其详细页面。
信息 定制资源定义(CRD)允许用户在不增加额外 API 服务器的情况下创建一种新的资源类型,用户可以像使用其他 Kubernetes 原生对象一样使用这些定制资源。
- 在自定义资源中,点击 ks-installer 右侧的 ,选择编辑 YAML。
- 在该 YAML 文件中,搜索
openpitrix,将enabled的false改为true。完成后,点击右下角的确定,保存配置。
openpitrix:
store:
enabled: true # 将“false”更改为“true”。
- 在 kubectl 中执行以下命令检查安装过程:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
备注 您可以通过点击控制台右下角的 找到 kubectl 工具。
验证组件的安装
在您登录控制台后,如果您能看到页面左上角的应用商店以及其中的应用,则说明安装成功。
备注:
- 您可以在不登录控制台的情况下直接访问
<IP 地址>:30880/apps进入应用商店。 - KubeSphere 3.2.x 中的应用商店启用后,
OpenPitrix页签不会显示在系统组件页面。
在多集群架构中使用应用商店
在多集群架构中,一个主集群管理所有成员集群。与 KubeSphere 中的其他组件不同,应用商店是所有集群(包括主集群和成员集群)的全局应用程序池。您只需要在主集群上启用应用商店,便可以直接在成员集群上使用应用商店的相关功能(无论成员集群是否启用应用商店),例如应用模板和应用仓库。
但是,如果只在成员集群上启用应用商店而没有在主集群上启用,您将无法在多集群架构中的任何集群上使用应用商店。
KubeSphere DevOps 系统
基于 Jenkins 的 KubeSphere DevOps 系统是专为 Kubernetes 中的 CI/CD 工作流设计的,它提供了一站式的解决方案,帮助开发和运维团队用非常简单的方式构建、测试和发布应用到 Kubernetes。它还具有插件管理、Binary-to-Image (B2I)、Source-to-Image (S2I)、代码依赖缓存、代码质量分析、流水线日志等功能。
DevOps 系统为用户提供了一个自动化的环境,应用可以自动发布到同一个平台。它还兼容第三方私有镜像仓库(如 Harbor)和代码库(如 GitLab/GitHub/SVN/BitBucket)。它为用户提供了全面的、可视化的 CI/CD 流水线,打造了极佳的用户体验,而且这种兼容性强的流水线能力在离线环境中非常有用。
在安装前启用 DevOps
在 Linux 上安装
当您在 Linux 上安装多节点 KubeSphere 时,首先需要创建一个配置文件,该文件列出了所有 KubeSphere 组件。
- 在 Linux 上安装 KubeSphere 时,您需要创建一个默认文件 config-sample.yaml,通过执行以下命令修改该文件:
vi config-sample.yaml
备注 如果您采用 All-in-one 安装,则不需要创建 config-sample.yaml 文件,因为可以直接创建集群。一般来说,All-in-one 模式是为那些刚接触 KubeSphere 并希望熟悉系统的用户而准备的,如果您想在这个模式下启用 DevOps(比如用于测试),请参考下面的部分,查看如何在安装后启用 DevOps。
- 在该文件中,搜索 devops,并将 enabled 的 false 改为 true,完成后保存文件。
devops:
enabled: true # 将“false”更改为“true”。
- 执行以下命令使用该配置文件创建集群:
./kk create cluster -f config-sample.yaml
在 Kubernetes 上安装
当您在 Kubernetes 上安装 KubeSphere 时,需要先在 cluster-configuration.yaml 文件中启用 DevOps。
- 下载
cluster-configuration.yaml文件,执行以下命令打开并编辑该文件:
vi cluster-configuration.yaml
- 在
cluster-configuration.yaml文件中,搜索devops,并将enabled的false改为true。完成后保存文件。
devops:
enabled: true # 将“false”更改为“true”。
- 执行以下命令开始安装:
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
在安装后启用 DevOps
- 以 admin 用户登录控制台,点击左上角的平台管理,选择集群管理。
- 点击 CRD,在搜索栏中输入 clusterconfiguration,点击搜索结果查看其详细页面。
信息 定制资源定义(CRD)允许用户在不新增 API 服务器的情况下创建一种新的资源类型,用户可以像使用其他 Kubernetes 原生对象一样使用这些定制资源。
- 在自定义资源中,点击
ks-installer右侧的 ,选择编辑 YAML。 - 在该 YAML 文件中,搜索 devops,将 enabled 的 false 改为 true。完成后,点击右下角的确定,保存配置。
devops:
enabled: true # 将“false”更改为“true”。
- 在
kubectl中执行以下命令检查安装过程:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
备注 您可以点击控制台右下角的 找到 kubectl 工具。
验证组件的安装
通过 kubectl 验证组件的安装
执行以下命令来检查容器组的状态:
kubectl get pod -n kubesphere-devops-system
如果组件运行成功,输出结果如下:
NAME READY STATUS RESTARTS AGE
devops-jenkins-5cbbfbb975-hjnll 1/1 Running 0 40m
s2ioperator-0 1/1 Running 0 41m
KubeSphere 日志系统
KubeSphere 为日志收集、查询和管理提供了一个强大的、全面的、易于使用的日志系统。它涵盖了不同层级的日志,包括租户、基础设施资源和应用。用户可以从项目、工作负载、容器组和关键字等不同维度对日志进行搜索。与 Kibana 相比,KubeSphere 基于租户的日志系统中,每个租户只能查看自己的日志,从而可以在租户之间提供更好的隔离性和安全性。除了 KubeSphere 自身的日志系统,该容器平台还允许用户添加第三方日志收集器,如 Elasticsearch、Kafka 和 Fluentd。
在安装前启用日志系统
在 Linux 上安装
当您在 Linux 上安装 KubeSphere 时,首先需要创建一个配置文件,该文件列出了所有 KubeSphere 组件。
- 在 Linux 上安装 KubeSphere 时,您需要创建一个默认文件 config-sample.yaml。通过执行以下命令修改该文件:
vi config-sample.yaml
备注 如果您采用 All-in-one 安装,则不需要创建 config-sample.yaml 文件,因为可以直接创建集群。一般来说,All-in-one 模式是为那些刚接触 KubeSphere 并希望熟悉系统的用户而准备的。如果您想在这个模式下启用日志系统(比如用于测试),请参考下面的部分,查看如何在安装后启用日志系统。 如果您采用多节点安装,并且使用符号链接作为 Docker 根目录,请确保所有节点遵循完全相同的符号链接。日志代理在守护进程集中部署到节点上。容器日志路径的任何差异都可能导致该节点的收集失败。
- 在该文件中,搜寻到 logging,并将 enabled 的 false 改为 true。完成后保存文件。
logging:
enabled: true # 将“false”更改为“true”。
containerruntime: docker
信息 若使用 containerd 作为容器运行时,请将 containerruntime 字段的值更改为 containerd。如果您从低版本升级至 KubeSphere 3.2.1,则启用 KubeSphere 日志系统时必须在 logging 字段下手动添加 containerruntime 字段。
备注 默认情况下,如果启用了日志系统,KubeKey 将安装内置 Elasticsearch。对于生产环境,如果您想启用日志系统,强烈建议在 config-sample.yaml 中设置以下值,尤其是 externalElasticsearchHost 和 externalElasticsearchPort。在安装前提供以下信息后,KubeKey 将直接对接您的外部 Elasticsearch,不再安装内置 Elasticsearch。
es: # Storage backend for logging, tracing, events and auditing.
elasticsearchMasterReplicas: 1 # The total number of master nodes. Even numbers are not allowed.
elasticsearchDataReplicas: 1 # The total number of data nodes.
elasticsearchMasterVolumeSize: 4Gi # The volume size of Elasticsearch master nodes.
elasticsearchDataVolumeSize: 20Gi # The volume size of Elasticsearch data nodes.
logMaxAge: 7 # Log retention day in built-in Elasticsearch. It is 7 days by default.
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log.
externalElasticsearchHost: # The Host of external Elasticsearch.
externalElasticsearchPort: # The port of external Elasticsearch.
- 使用该配置文件创建集群:
./kk create cluster -f config-sample.yaml
在 Kubernetes 上安装
当您在 Kubernetes 上安装 KubeSphere 时,需要先在 cluster-configuration.yaml 文件中启用日志系统。
- 下载
cluster-configuration.yaml文件,然后打开并开始编辑。
vi cluster-configuration.yaml
- 在
cluster-configuration.yaml文件中,搜索 logging,并将 enabled 的 false 改为 true,以启用日志系统。完成后保存文件。
logging:
enabled: true # 将“false”更改为“true”。
containerruntime: docker
信息 若使用 containerd 作为容器运行时,请将 .logging.containerruntime 字段的值更改为 containerd。如果您从低版本升级至 KubeSphere 3.2.1,则启用 KubeSphere 日志系统时必须在 logging 字段下手动添加 containerruntime 字段。
备注 默认情况下,如果启用了日志系统,ks-installer 将安装内置 Elasticsearch。对于生产环境,如果您想启用日志系统,强烈建议在 cluster-configuration.yaml 中设置以下值,尤其是 externalElasticsearchHost 和 externalElasticsearchPort。在安装前提供以下信息后,ks-installer 将直接对接您的外部 Elasticsearch,不再安装内置 Elasticsearch。
es: # Storage backend for logging, tracing, events and auditing.
elasticsearchMasterReplicas: 1 # The total number of master nodes. Even numbers are not allowed.
elasticsearchDataReplicas: 1 # The total number of data nodes.
elasticsearchMasterVolumeSize: 4Gi # The volume size of Elasticsearch master nodes.
elasticsearchDataVolumeSize: 20Gi # The volume size of Elasticsearch data nodes.
logMaxAge: 7 # Log retention day in built-in Elasticsearch. It is 7 days by default.
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log.
externalElasticsearchHost: # The Host of external Elasticsearch.
externalElasticsearchPort: # The port of external Elasticsearch.
- 执行以下命令开始安装:
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
在安装后启用日志系统
- 以 admin 用户登录控制台。点击左上角的平台管理,选择集群管理。
- 点击 CRD,在搜索栏中输入 clusterconfiguration。点击结果查看其详细页面。
信息 定制资源定义 (CRD) 允许用户在不增加额外 API 服务器的情况下创建一种新的资源类型,用户可以像使用其他 Kubernetes 原生对象一样使用这些定制资源。
- 在自定义资源中,点击
ks-installer右侧的 ,选择编辑 YAML。 - 在该 YAML 文件中,搜索 logging,将 enabled 的 false 改为 true。完成后,点击右下角的确定以保存配置。
logging:
enabled: true # 将“false”更改为“true”。
containerruntime: docker
信息 若使用 containerd 作为容器运行时,请将 .logging.containerruntime 字段的值更改为 containerd。如果您从低版本升级至 KubeSphere 3.2.1,则启用 KubeSphere 日志系统时必须在 logging 字段下手动添加 containerruntime 字段。
备注 默认情况下,如果启用了日志系统,将会安装内置 Elasticsearch。对于生产环境,如果您想启用日志系统,强烈建议在该 YAML 文件中设置以下值,尤其是 externalElasticsearchHost 和 externalElasticsearchPort。在文件中提供以下信息后,KubeSphere 将直接对接您的外部 Elasticsearch,不再安装内置 Elasticsearch。
es: # Storage backend for logging, tracing, events and auditing.
elasticsearchMasterReplicas: 1 # The total number of master nodes. Even numbers are not allowed.
elasticsearchDataReplicas: 1 # The total number of data nodes.
elasticsearchMasterVolumeSize: 4Gi # The volume size of Elasticsearch master nodes.
elasticsearchDataVolumeSize: 20Gi # The volume size of Elasticsearch data nodes.
logMaxAge: 7 # Log retention day in built-in Elasticsearch. It is 7 days by default.
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log.
externalElasticsearchHost: # The Host of external Elasticsearch.
externalElasticsearchPort: # The port of external Elasticsearch.
- 在 kubectl 中执行以下命令检查安装过程:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
备注 您可以通过点击控制台右下角的 找到 kubectl 工具。
验证组件的安装
通过 kubectl 验证组件的安装
执行以下命令来检查容器组的状态:
kubectl get pod -n kubesphere-logging-system
如果组件运行成功,输出结果如下:
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-data-0 1/1 Running 0 87m
elasticsearch-logging-data-1 1/1 Running 0 85m
elasticsearch-logging-discovery-0 1/1 Running 0 87m
fluent-bit-bsw6p 1/1 Running 0 40m
fluent-bit-smb65 1/1 Running 0 40m
fluent-bit-zdz8b 1/1 Running 0 40m
fluentbit-operator-9b69495b-bbx54 1/1 Running 0 40m
logsidecar-injector-deploy-667c6c9579-cs4t6 2/2 Running 0 38m
logsidecar-injector-deploy-667c6c9579-klnmf 2/2 Running 0 38m
KubeSphere 事件系统
KubeSphere 事件系统使用户能够跟踪集群内部发生的事件,例如节点调度状态和镜像拉取结果。这些事件会被准确记录下来,并在 Web 控制台中显示具体的原因、状态和信息。要查询事件,用户可以快速启动 Web 工具箱,在搜索栏中输入相关信息,并有不同的过滤器(如关键字和项目)可供选择。事件也可以归档到第三方工具,例如 Elasticsearch、Kafka 或 Fluentd。
在安装前启用事件系统
在 Linux 上安装
当您在 Linux 上安装多节点 KubeSphere 时,需要创建一个配置文件,该文件列出了所有 KubeSphere 组件。
- 在 Linux 上安装 KubeSphere 时,您需要创建一个默认文件 config-sample.yaml。执行以下命令修改该文件:
vi config-sample.yaml
备注 如果您采用 All-in-One 安装,则不需要创建 config-sample.yaml 文件,因为可以直接创建集群。一般来说,All-in-One 模式是为那些刚接触 KubeSphere 并希望熟悉系统的用户而准备的。如果您想在该模式下启用事件系统(例如用于测试),请参考下面的部分,查看如何在安装后启用事件系统。
- 在该文件中,搜寻到 events,并将 enabled 的 false 改为 true。完成后保存文件。
events:
enabled: true # 将“false”更改为“true”。
备注 默认情况下,如果启用了事件系统,`KubeKey` 将安装内置 `Elasticsearch`。对于生产环境,如果您想启用事件系统,强烈建议在 config-sample.yaml 中设置以下值,尤其是 externalElasticsearchHost 和 externalElasticsearchPort。在安装前提供以下信息后,KubeKey 将直接对接您的外部 Elasticsearch,不再安装内置 Elasticsearch。
es: # Storage backend for logging, tracing, events and auditing.
elasticsearchMasterReplicas: 1 # The total number of master nodes. Even numbers are not allowed.
elasticsearchDataReplicas: 1 # The total number of data nodes.
elasticsearchMasterVolumeSize: 4Gi # The volume size of Elasticsearch master nodes.
elasticsearchDataVolumeSize: 20Gi # The volume size of Elasticsearch data nodes.
logMaxAge: 7 # Log retention day in built-in Elasticsearch. It is 7 days by default.
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log.
externalElasticsearchHost: # The Host of external Elasticsearch.
externalElasticsearchPort: # The port of external Elasticsearch.
- 使用该配置文件创建集群:
./kk create cluster -f config-sample.yaml
在 Kubernetes 上安装
当您在 Kubernetes 上安装 KubeSphere 时,需要先在 cluster-configuration.yaml 文件中启用事件系统。
- 下载 cluster-configuration.yaml 文件,然后打开并开始编辑。
vi cluster-configuration.yaml
- 在
cluster-configuration.yaml文件中,搜索 events,并将 enabled 的 false 改为 true以启用事件系统。完成后保存文件。
events:
enabled: true # 将“false”更改为“true”。
备注 对于生产环境,如果您想启用事件系统,强烈建议在 cluster-configuration.yaml 中设置以下值,尤其是 externalElasticsearchHost 和 externalElasticsearchPort。在安装前提供以下信息后,ks-installer 将直接对接您的外部 Elasticsearch,不再安装内置 Elasticsearch。
es: # Storage backend for logging, tracing, events and auditing.
elasticsearchMasterReplicas: 1 # The total number of master nodes. Even numbers are not allowed.
elasticsearchDataReplicas: 1 # The total number of data nodes.
elasticsearchMasterVolumeSize: 4Gi # The volume size of Elasticsearch master nodes.
elasticsearchDataVolumeSize: 20Gi # The volume size of Elasticsearch data nodes.
logMaxAge: 7 # Log retention day in built-in Elasticsearch. It is 7 days by default.
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log.
externalElasticsearchHost: # The Host of external Elasticsearch.
externalElasticsearchPort: # The port of external Elasticsearch.
- 执行以下命令开始安装:
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
在安装后启用事件系统
- 使用 admin 用户登录控制台。点击左上角的平台管理,选择集群管理。
- 点击 CRD,在搜索栏中输入 clusterconfiguration。点击结果查看其详情页。
信息 定制资源定义 (CRD) 允许用户在不新增 API 服务器的情况下创建一种新的资源类型,用户可以像使用其他 Kubernetes 原生对象一样使用这些定制资源。
- 在自定义资源中,点击 ks-installer 右侧的 ,选择编辑 YAML。
- 在该配置文件中,搜索 events,将 enabled 的 false 改为 true。完成后,点击右下角的确定,保存配置。
events:
enabled: true # 将“false”更改为“true”。
备注 默认情况下,如果启用了事件系统,将会安装内置 Elasticsearch。对于生产环境,如果您想启用事件系统,强烈建议在该 YAML 文件中设置以下值,尤其是 externalElasticsearchHost 和 externalElasticsearchPort。在文件中提供以下信息后,KubeSphere 将直接对接您的外部 Elasticsearch,不再安装内置 Elasticsearch。
es: # Storage backend for logging, tracing, events and auditing.
elasticsearchMasterReplicas: 1 # The total number of master nodes. Even numbers are not allowed.
elasticsearchDataReplicas: 1 # The total number of data nodes.
elasticsearchMasterVolumeSize: 4Gi # The volume size of Elasticsearch master nodes.
elasticsearchDataVolumeSize: 20Gi # The volume size of Elasticsearch data nodes.
logMaxAge: 7 # Log retention day in built-in Elasticsearch. It is 7 days by default.
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log.
externalElasticsearchHost: # The Host of external Elasticsearch.
externalElasticsearchPort: # The port of external Elasticsearch.
- 在 kubectl 中执行以下命令检查安装过程:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
备注 您可以通过点击控制台右下角的 找到 `kubectl` 工具。
验证组件的安装
通过 kubectl 验证组件的安装
执行以下命令来检查容器组的状态:
kubectl get pod -n kubesphere-logging-system
如果组件运行成功,输出结果如下:
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-data-0 1/1 Running 0 155m
elasticsearch-logging-data-1 1/1 Running 0 154m
elasticsearch-logging-discovery-0 1/1 Running 0 155m
fluent-bit-bsw6p 1/1 Running 0 108m
fluent-bit-smb65 1/1 Running 0 108m
fluent-bit-zdz8b 1/1 Running 0 108m
fluentbit-operator-9b69495b-bbx54 1/1 Running 0 109m
ks-events-exporter-5cb959c74b-gx4hw 2/2 Running 0 7m55s
ks-events-operator-7d46fcccc9-4mdzv 1/1 Running 0 8m
ks-events-ruler-8445457946-cl529 2/2 Running 0 7m55s
ks-events-ruler-8445457946-gzlm9 2/2 Running 0 7m55s
logsidecar-injector-deploy-667c6c9579-cs4t6 2/2 Running 0 106m
logsidecar-injector-deploy-667c6c9579-klnmf 2/2 Running 0 106m
KubeSphere 告警系统
告警是可观测性的重要组成部分,与监控和日志密切相关。KubeSphere 中的告警系统与其主动式故障通知 (Proactive Failure Notification) 系统相结合,使用户可以基于告警策略了解感兴趣的活动。当达到某个指标的预定义阈值时,会向预先配置的收件人发出告警。因此,您需要预先配置通知方式,包括邮件、Slack、钉钉、企业微信和 Webhook。有了功能强大的告警和通知系统,您就可以迅速发现并提前解决潜在问题,避免您的业务受影响。
在安装前启用告警系统
在 Linux 上安装
当您在 Linux 上安装多节点 KubeSphere 时,需要创建一个配置文件,该文件列出了所有 KubeSphere 组件。
- 在 Linux 上安装 KubeSphere 时,您需要创建一个默认文件 config-sample.yaml。通过执行以下命令修改该文件:
vi config-sample.yaml
备注 如果您采用 All-in-One 安装,则不需要创建 config-sample.yaml 文件,因为可以直接创建集群。一般来说,All-in-One 模式针对那些刚接触 KubeSphere 并希望熟悉系统的用户。如果您想在该模式下启用告警系统(例如用于测试),请参考下面的部分,查看如何在安装后启用告警系统。
- 在该文件中,搜索 alerting 并将 enabled 的 false 更改为 true。完成后保存文件。
alerting:
enabled: true # 将“false”更改为“true”。
- 执行以下命令使用该配置文件创建集群:
./kk create cluster -f config-sample.yaml
在 Kubernetes 上安装
当您在 Kubernetes 上安装 KubeSphere 时,需要先在 cluster-configuration.yaml 文件中启用告警系统。
- 下载
cluster-configuration.yaml文件并进行编辑。
vi cluster-configuration.yaml
- 在
cluster-configuration.yaml文件中,搜索alerting,将enabled的false更改为true以启用告警系统。完成后保存文件。
alerting:
enabled: true # 将“false”更改为“true”。
- 执行以下命令开始安装:
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
在安装后启用告警系统
- 使用 admin 用户登录控制台。点击左上角的平台管理,选择集群管理。
- 点击 CRD,在搜索栏中输入 clusterconfiguration。点击结果查看其详细页面。
信息 定制资源定义 (CRD) 允许用户在不新增 API 服务器的情况下创建一种新的资源类型,用户可以像使用其他 Kubernetes 原生对象一样使用这些定制资源。
- 在自定义资源中,点击
ks-installer右侧,选择编辑 YAML。 - 在该
YAML文件中,搜寻到alerting,将enabled的false更改为true。完成后,点击右下角的确定,保存配置。
alerting:
enabled: true # 将“false”更改为“true”。
- 在 kubectl 中执行以下命令检查安装过程:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
备注 您可以通过点击控制台右下角的 找到 `kubectl` 工具。
验证组件的安装
如果您可以在集群管理页面看到告警消息和告警策略,则说明安装成功。
KubeSphere 审计日志
KubeSphere 审计日志系统提供了一套与安全相关并按时间顺序排列的记录,按顺序记录了与单个用户、管理人员或系统其他组件相关的活动。对 KubeSphere 的每个请求都会生成一个事件,然后写入 Webhook,并根据一定的规则进行处理。
在安装前启用审计日志
在 Linux 上安装
当您在 Linux 上安装多节点 KubeSphere 时,需要创建一个配置文件,该文件列出了所有 KubeSphere 组件。
- 在 Linux 上安装 KubeSphere 时,您需要创建一个默认文件 config-sample.yaml。执行以下命令修改该文件:
vi config-sample.yaml
备注 如果您采用 All-in-One 安装,则不需要创建 config-sample.yaml 文件,因为可以直接创建集群。一般来说,All-in-One 模式是为那些刚接触 KubeSphere 并希望熟悉系统的用户而准备的,如果您想在该模式下启用审计日志(例如用于测试),请参考下面的部分,查看如何在安装后启用审计功能。
- 在该文件中,搜索
auditing,并将enabled的false改为true。完成后保存文件。
auditing:
enabled: true # 将“false”更改为“true”。
备注 默认情况下,如果启用了审计功能,KubeKey 将安装内置 Elasticsearch。对于生产环境,如果您想启用审计功能,强烈建议在 config-sample.yaml 中设置以下值,尤其是 externalElasticsearchHost 和 externalElasticsearchPort。在安装前提供以下信息后,KubeKey 将直接对接您的外部 Elasticsearch,不再安装内置 Elasticsearch。
es: # Storage backend for logging, tracing, events and auditing.
elasticsearchMasterReplicas: 1 # The total number of master nodes. Even numbers are not allowed.
elasticsearchDataReplicas: 1 # The total number of data nodes.
elasticsearchMasterVolumeSize: 4Gi # The volume size of Elasticsearch master nodes.
elasticsearchDataVolumeSize: 20Gi # The volume size of Elasticsearch data nodes.
logMaxAge: 7 # Log retention day in built-in Elasticsearch. It is 7 days by default.
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log.
externalElasticsearchHost: # The Host of external Elasticsearch.
externalElasticsearchPort: # The port of external Elasticsearch.
- 执行以下命令使用该配置文件创建集群:
./kk create cluster -f config-sample.yaml
在 Kubernetes 上安装
当您在 Kubernetes 上安装 KubeSphere 时,需要先在 cluster-configuration.yaml 文件中启用审计功能。
- 下载 cluster-configuration.yaml 文件,执行以下命令打开并编辑该文件:
vi cluster-configuration.yaml
- 在
cluster-configuration.yaml文件中,搜索auditing,并将enabled的false改为true。完成后保存文件。
auditing:
enabled: true # 将“false”更改为“true”。
备注 默认情况下,如果启用了审计功能,ks-installer 会安装内置 Elasticsearch。对于生产环境,如果您想启用审计功能,强烈建议在 cluster-configuration.yaml 中设置以下值,尤其是 externalElasticsearchHost 和 externalElasticsearchPort。在安装前提供以下信息后,ks-installer 将直接对接您的外部 Elasticsearch,不再安装内置 Elasticsearch。
es: # Storage backend for logging, tracing, events and auditing.
elasticsearchMasterReplicas: 1 # The total number of master nodes. Even numbers are not allowed.
elasticsearchDataReplicas: 1 # The total number of data nodes.
elasticsearchMasterVolumeSize: 4Gi # The volume size of Elasticsearch master nodes.
elasticsearchDataVolumeSize: 20Gi # The volume size of Elasticsearch data nodes.
logMaxAge: 7 # Log retention day in built-in Elasticsearch. It is 7 days by default.
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log.
externalElasticsearchHost: # The Host of external Elasticsearch.
externalElasticsearchPort: # The port of external Elasticsearch.
- 执行以下命令开始安装:
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
在安装后启用审计日志
- 以 admin 用户登录控制台。点击左上角的平台管理,选择集群管理。
- 点击 CRD,在搜索栏中输入 clusterconfiguration,点击搜索结果查看其详细页面。
信息 定制资源定义 (CRD) 允许用户在不新增 API 服务器的情况下创建一种新的资源类型,用户可以像使用其他 Kubernetes 原生对象一样使用这些定制资源。
- 在自定义资源中,点击
ks-installer右侧的 ,选择编辑 YAML。 - 在该
YAML文件中,搜索auditing,将enabled的false改为true。完成后,点击右下角的确定,保存配置。
auditing:
enabled: true # 将“false”更改为“true”。
备注 默认情况下,如果启用了审计功能,将安装内置 Elasticsearch。对于生产环境,如果您想启用审计功能,强烈建议在该 YAML 文件中设置以下值,尤其是 externalElasticsearchHost 和 externalElasticsearchPort。提供以下信息后,KubeSphere 将直接对接您的外部 Elasticsearch,不再安装内置 Elasticsearch。
es: # Storage backend for logging, tracing, events and auditing.
elasticsearchMasterReplicas: 1 # The total number of master nodes. Even numbers are not allowed.
elasticsearchDataReplicas: 1 # The total number of data nodes.
elasticsearchMasterVolumeSize: 4Gi # The volume size of Elasticsearch master nodes.
elasticsearchDataVolumeSize: 20Gi # The volume size of Elasticsearch data nodes.
logMaxAge: 7 # Log retention day in built-in Elasticsearch. It is 7 days by default.
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log.
externalElasticsearchHost: # The Host of external Elasticsearch.
externalElasticsearchPort: # The port of external Elasticsearch.
- 在 kubectl 中执行以下命令检查安装过程:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
备注 您可以点击控制台右下角的 找到 kubectl 工具。
验证组件的安装
通过 kubectl 验证组件的安装
执行以下命令来检查容器组的状态:
kubectl get pod -n kubesphere-logging-system
如果组件运行成功,输出结果如下:
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-curator-elasticsearch-curator-159872n9g9g 0/1 Completed 0 2d10h
elasticsearch-logging-curator-elasticsearch-curator-159880tzb7x 0/1 Completed 0 34h
elasticsearch-logging-curator-elasticsearch-curator-1598898q8w7 0/1 Completed 0 10h
elasticsearch-logging-data-0 1/1 Running 1 2d20h
elasticsearch-logging-data-1 1/1 Running 1 2d20h
elasticsearch-logging-discovery-0 1/1 Running 1 2d20h
fluent-bit-6v5fs 1/1 Running 1 2d20h
fluentbit-operator-5bf7687b88-44mhq 1/1 Running 1 2d20h
kube-auditing-operator-7574bd6f96-p4jvv 1/1 Running 1 2d20h
kube-auditing-webhook-deploy-6dfb46bb6c-hkhmx 1/1 Running 1 2d20h
kube-auditing-webhook-deploy-6dfb46bb6c-jp77q 1/1 Running 1 2d20h
KubeSphere 服务网格
KubeSphere 服务网格基于 Istio,将微服务治理和流量管理可视化。它拥有强大的工具包,包括熔断机制、蓝绿部署、金丝雀发布、流量镜像、链路追踪、可观测性和流量控制等。KubeSphere 服务网格支持代码无侵入的微服务治理,帮助开发者快速上手,Istio 的学习曲线也极大降低。KubeSphere 服务网格的所有功能都旨在满足用户的业务需求。
在安装前启用服务网格
在 Linux 上安装
当您在 Linux 上安装多节点 KubeSphere 时,需要创建一个配置文件,该文件列出了所有 KubeSphere 组件。
- 在 Linux 上安装 KubeSphere 时,您需要创建一个默认文件 config-sample.yaml。执行以下命令修改该文件:
vi config-sample.yaml
备注 如果您采用 All-in-One 安装,则不需要创建 config-sample.yaml 文件,因为可以直接创建集群。一般来说,All-in-One 模式是为那些刚接触 KubeSphere 并希望熟悉系统的用户而准备的。如果您想在该模式下启用服务网格(例如用于测试),请参考下面的部分,查看如何在安装后启用服务网格。
- 在该文件中,搜索 servicemesh,并将 enabled 的 false 改为 true。完成后保存文件。
servicemesh:
enabled: true # 将“false”更改为“true”。
- 执行以下命令使用该配置文件创建集群:
./kk create cluster -f config-sample.yaml
在 Kubernetes 上安装
当您在 Kubernetes 上安装 KubeSphere 时,需要先在 cluster-configuration.yaml 文件中启用服务网格。
- 下载
cluster-configuration.yaml文件,执行以下命令打开并编辑该文件:
vi cluster-configuration.yaml
- 在
cluster-configuration.yaml文件中,搜索servicemesh,并将enabled的false改为true。完成后保存文件。
servicemesh:
enabled: true # 将“false”更改为“true”。
- 执行以下命令开始安装:
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
在安装后启用服务网格
- 以 admin 用户登录控制台。点击左上角的平台管理,选择集群管理。
- 点击 CRD,在搜索栏中输入 clusterconfiguration。点击结果查看其详情页。
信息 定制资源定义(CRD)允许用户在不新增 API 服务器的情况下创建一种新的资源类型,用户可以像使用其他 Kubernetes 原生对象一样使用这些定制资源。
- 在自定义资源中,点击 ks-installer 右侧的 ,选择编辑 YAML。
- 在该配置文件中,搜索
servicemesh,并将enabled的false改为true。完成后,点击右下角的确定,保存配置。
servicemesh:
enabled: true # 将“false”更改为“true”。
- 在 kubectl 中执行以下命令检查安装过程:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
备注 您可以通过点击控制台右下角的 找到 kubectl 工具。
验证组件的安装
通过 kubectl 验证组件的安装
执行以下命令检查容器组的状态:
kubectl get pod -n istio-system
如果组件运行成功,输出结果可能如下:
NAME READY STATUS RESTARTS AGE
istio-ingressgateway-78dbc5fbfd-f4cwt 1/1 Running 0 9m5s
istiod-1-6-10-7db56f875b-mbj5p 1/1 Running 0 10m
jaeger-collector-76bf54b467-k8blr 1/1 Running 0 6m48s
jaeger-operator-7559f9d455-89hqm 1/1 Running 0 7m
jaeger-query-b478c5655-4lzrn 2/2 Running 0 6m48s
kiali-f9f7d6f9f-gfsfl 1/1 Running 0 4m1s
kiali-operator-7d5dc9d766-qpkb6 1/1 Running 0 6m53s
网络策略
从 3.0.0 版本开始,用户可以在 KubeSphere 中配置原生 Kubernetes 的网络策略。网络策略是一种以应用为中心的结构,使您能够指定如何允许容器组通过网络与各种网络实体进行通信。通过网络策略,用户可以在同一集群内实现网络隔离,这意味着可以在某些实例(容器组)之间设置防火墙。
备注 在启用之前,请确保集群使用的 CNI 网络插件支持网络策略。支持网络策略的 CNI 网络插件有很多,包括 Calico、Cilium、Kube-router、Romana 和 Weave Net 等。 建议您在启用网络策略之前,使用 Calico 作为 CNI 插件。
在安装前启用网络策略
在 Linux 上安装
当您在 Linux 上安装多节点 KubeSphere 时,需要创建一个配置文件,该文件列出了所有 KubeSphere 组件。
- 在
在 Linux 上安装 KubeSphere时,您需要创建一个默认文件config-sample.yaml。执行以下命令修改该文件:
vi config-sample.yaml
备注 如果您采用 All-in-One 安装,则不需要创建 config-sample.yaml 文件,因为可以直接创建集群。一般来说,All-in-One 模式是为那些刚接触 KubeSphere 并希望熟悉系统的用户而准备的。如果您想在该模式下启用网络策略(例如用于测试),可以参考下面的部分,查看如何在安装后启用网络策略。
- 在该文件中,搜索 network.networkpolicy,并将 enabled 的 false 改为 true。完成后保存文件。
network:
networkpolicy:
enabled: true # 将“false”更改为“true”。
- 使用配置文件创建一个集群:
./kk create cluster -f config-sample.yaml
在 Kubernetes 上安装
当您在 Kubernetes 上安装 KubeSphere 时,需要先在 cluster-configuration.yaml 文件中启用网络策略。
- 下载
cluster-configuration.yaml文件,然后打开并开始编辑。
vi cluster-configuration.yaml
- 在该本地
cluster-configuration.yaml文件中,搜索 network.networkpolicy,并将 enabled 的 false 改为 true。完成后保存文件。
network:
networkpolicy:
enabled: true # 将“false”更改为“true”。
- 执行以下命令开始安装:
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
在安装后启用网络策略
- 以 admin 身份登录控制台。点击左上角的平台管理,选择集群管理。
- 点击
CRD,在搜索栏中输入 clusterconfiguration。点击结果查看其详细页面。
信息 定制资源定义(CRD)允许用户在不新增 API 服务器的情况下创建一种新的资源类型,用户可以像使用其他 Kubernetes 原生对象一样使用这些定制资源。
- 在自定义资源中,点击 ks-installer 右侧的 ,选择编辑 YAML。
- 在该 YAML 文件中,搜寻到 network.networkpolicy,将 enabled 的 false 改为 true。完成后,点击右下角的确定,保存配置。
network:
networkpolicy:
enabled: true # 将“false”更改为“true”。
- 在 kubectl 中执行以下命令检查安装过程:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
验证组件的安装
如果您能在网络中看到网络策略,说明安装成功。
Metrics Server
KubeSphere 支持用于部署的容器组(Pod)弹性伸缩程序 (HPA)。在 KubeSphere 中,Metrics Server 控制着 HPA 是否启用。您可以根据不同类型的指标(例如 CPU 和内存使用率,以及最小和最大副本数),使用 HPA 对象对部署 (Deployment) 自动伸缩。通过这种方式,HPA 可以帮助确保您的应用程序在不同情况下都能平稳、一致地运行。
在安装前启用 Metrics Server
在 Linux 上安装
当您在 Linux 上安装多节点 KubeSphere 时,首先需要创建一个配置文件,该文件列出了所有 KubeSphere 组件。
- 在
Linux 上安装 KubeSphere时,您需要创建一个默认文件config-sample.yaml,通过执行以下命令修改该文件:
vi config-sample.yaml
备注 如果您采用 All-in-One 安装,则不需要创建 `config-sample.yaml` 文件,因为可以直接创建集群。一般来说,All-in-One 模式是为那些刚接触 KubeSphere 并希望熟悉系统的用户而准备的。如果您想在这个模式下启用 Metrics Server(比如用于测试),请参考下面的部分,查看如何在安装后启用 Metrics Server。
- 在该文件中,搜寻到
metrics_server,并将enabled的false改为true。完成后保存文件。
metrics_server:
enabled: true # 将“false”更改为“true”。
- 使用该配置文件创建集群:
./kk create cluster -f config-sample.yaml
在 Kubernetes 上安装
当您在 Kubernetes 上安装 KubeSphere 时,需要先在 cluster-configuration.yaml 文件中先启用 Metrics Server组件。
- 下载文件
cluster-configuration.yaml,并打开文件进行编辑。
vi cluster-configuration.yaml
- 在
cluster-configuration.yaml中,搜索metrics_server,并将enabled的false改为true。完成后保存文件。
metrics_server:
enabled: true # 将“false”更改为“true”。
3.执行以下命令以开始安装:
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
备注 如果您在某些云托管的 Kubernetes 引擎上安装 KubeSphere,那么很可能您的环境中已经安装了 Metrics Server。在这种情况下,不建议您在 cluster-configuration.yaml 中启用 Metrics Server,因为这可能会在安装过程中引起冲突。
在安装后启用 Metrics Server
- 以 admin 用户登录控制台。点击左上角平台管理,选择集群管理。
- 点击
CRD,在搜索栏中输入clusterconfiguration。点击搜索结果查看详情页。
信息 定制资源定义(CRD)允许用户在不增加额外 API 服务器的情况下创建一种新的资源类型,用户可以像使用其他 Kubernetes 原生对象一样使用这些定制资源。
- 在自定义资源中,点击
ks-installer右侧的 ,选择编辑 YAML。 - 在该
YAML文件中,搜索metrics_server,将enabled的false改为true。完成后,点击右下角的确定以保存配置。
metrics_server:
enabled: true # 将“false”更改为“true”。
- 在 kubectl 中执行以下命令检查安装过程:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
验证组件的安装
执行以下命令以验证 Metrics Server 的容器组是否正常运行:
kubectl get pod -n kube-system
如果 Metrics Server 安装成功,那么集群可能会返回以下输出(不包括无关容器组):
NAME READY STATUS RESTARTS AGE
metrics-server-6c767c9f94-hfsb7 1/1 Running 0 9m38s
服务拓扑图
您可以启用服务拓扑图以集成 Weave Scope(Docker 和 Kubernetes 的可视化和监控工具)。Weave Scope 使用既定的 API 收集信息,为应用和容器构建拓扑图。服务拓扑图显示在您的项目中,将服务之间的连接关系可视化。
安装前启用服务拓扑图
在 Linux 上安装
在 Linux 上多节点安装 KubeSphere 时,您需要创建一个配置文件,该文件会列出所有 KubeSphere 组件。
- 在 Linux 上安装 KubeSphere 时,您需要创建一个默认文件
config-sample.yaml。执行以下命令修改该文件:
vi config-sample.yaml
备注 如果您采用 All-in-one 安装,则不需要创建 `config-sample.yaml` 文件,因为可以直接创建集群。一般来说,All-in-one 模式针对那些刚接触 KubeSphere 并希望熟悉系统的用户。如果您想在该模式下启用服务拓扑图(比如用于测试),请参考下面的部分,查看如何在安装后启用服务拓扑图。
- 在该文件中,搜索
network.topology.type,并将none改为weave-scope。完成后保存文件。
network:
topology:
type: weave-scope # 将“none”更改为“weave-scope”。
- 执行以下命令使用该配置文件创建集群:
./kk create cluster -f config-sample.yaml
在 Kubernetes 上安装
当您在 Kubernetes 上安装 KubeSphere 时,需要先在cluster-configuration.yaml 文件中启用服务拓扑图。
- 下载 cluster-configuration.yaml 文件并进行编辑。
vi cluster-configuration.yaml
- 在
cluster-configuration.yaml文件中,搜索network.topology.type,将none更改为weave-scope以启用服务拓扑图。完成后保存文件。
network:
topology:
type: weave-scope # 将“none”更改为“weave-scope”。
- 执行以下命令开始安装:
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
在安装后启用服务拓扑图
- 以 admin 用户登录控制台。点击左上角的平台管理,然后选择集群管理。
- 点击 CRD,然后在搜索栏中输入 clusterconfiguration。点击搜索结果查看其详情页。
信息 定制资源定义(CRD)允许用户在不新增 API 服务器的情况下创建一种新的资源类型,用户可以像使用其他 Kubernetes 原生对象一样使用这些定制资源。
- 在自定义资源中,点击 ks-installer 右侧的 ,然后选择编辑 YAML。
- 在该配置文件中,搜寻到 network,将 network.topology.type 更改为 weave-scope。完成后,点击右下角的确定保存配置。
network:
topology:
type: weave-scope # 将“none”更改为“weave-scope”。
- 在 kubectl 中执行以下命令检查安装过程:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
验证组件的安装
通过 kubectl 验证组件的安装
执行以下命令来检查容器组的状态:
kubectl get pod -n weave
如果组件运行成功,输出结果可能如下:
NAME READY STATUS RESTARTS AGE
weave-scope-agent-48cjp 1/1 Running 0 3m1s
weave-scope-agent-9jb4g 1/1 Running 0 3m1s
weave-scope-agent-ql5cf 1/1 Running 0 3m1s
weave-scope-app-5b76897b6f-8bsls 1/1 Running 0 3m1s
weave-scope-cluster-agent-8d9b8c464-5zlpp 1/1 Running 0 3m1s
容器组 IP 池
容器组 IP 池用于规划容器组网络地址空间,每个容器组 IP 池之间的地址空间不能重叠。创建工作负载时,可选择特定的容器组 IP 池,这样创建出的容器组将从该容器组 IP 池中分配 IP 地址。
安装前启用容器组 IP 池
在 Linux 上安装
在 Linux 上多节点安装 KubeSphere 时,您需要创建一个配置文件,该文件会列出所有 KubeSphere 组件。
- 在 Linux 上安装 KubeSphere 时,您需要创建一个默认文件 config-sample.yaml。执行以下命令修改该文件:
vi config-sample.yaml
备注 如果您采用 All-in-one 安装,则不需要创建 config-sample.yaml 文件,因为可以直接创建集群。一般来说,All-in-one 模式针对那些刚接触 KubeSphere 并希望熟悉系统的用户。如果您想在该模式下启用容器组 IP 池(比如用于测试),请参考下面的部分,查看如何在安装后启用容器组 IP 池。
- 在该文件中,搜索 network.ippool.type,然后将 none 更改为 calico。完成后保存文件。
network:
ippool:
type: calico # 将“none”更改为“calico”。
- 使用该配置文件创建一个集群:
./kk create cluster -f config-sample.yaml
在 Kubernetes 上安装
当您在 Kubernetes 上安装 KubeSphere 时,需要现在 cluster-configuration.yaml 文件中启用容器组 IP 池。
- 下载
cluster-configuration.yaml文件并进行编辑。
vi cluster-configuration.yaml
- 在本地
cluster-configuration.yaml文件中,搜索network.ippool.type,将none更改为calico以启用容器组 IP 池。完成后保存文件。
network:
ippool:
type: calico # 将“none”更改为“calico”。
- 执行以下命令开始安装。
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
在安装后启用容器组 IP 池
- 使用 admin 用户登录控制台。点击左上角的平台管理,然后选择集群管理。
- 点击 CRD,然后在搜索栏中输入 clusterconfiguration。点击搜索结果查看其详情页。
信息 定制资源定义(CRD)允许用户在不新增 API 服务器的情况下创建一种新的资源类型,用户可以像使用其他 Kubernetes 原生对象一样使用这些定制资源。
- 在自定义资源中,点击 ks-installer 右侧的 ,然后选择编辑 YAML。
- 在该配置文件中,搜寻到 network,将 network.ippool.type 更改为 calico。完成后,点击右下角的确定保存配置。
network:
ippool:
type: calico # 将“none”更改为“calico”。
- 在 kubectl 中执行以下命令检查安装过程:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
验证组件的安装
在集群管理页面,您可以在网络下看到容器组 IP 池。
KubeSphere 3.2.x 卸载可插拔组件
启用 KubeSphere 可插拔组件之后,还可以根据以下步骤卸载他们。请在卸载这些组件之前,备份所有重要数据。
备注 KubeSphere 3.2.x 卸载某些可插拔组件的方法与 KubeSphere v3.0.0 不相同。有关 KubeSphere v3.0.0 卸载可插拔组件的详细方法,请参阅从 KubeSphere 上卸载可插拔组件](https://v3-0.docs.kubesphere.io/zh/docs/faq/installation/uninstall-pluggable-components/)。
准备工作
在卸载除服务拓扑图和容器组 IP 池之外的可插拔组件之前,必须将 CRD 配置文件 ClusterConfiguration 中的 ks-installer 中的 enabled 字段的值从 true 改为 false。
使用下列任一方法更改 enabled 字段的值:
- 运行以下命令编辑 ks-installer:
kubectl -n kubesphere-system edit clusterconfiguration ks-installer
- 使用 admin 身份登录 KubeSphere Web 控制台,左上角点击平台管理,选择集群管理,在自定义资源 CRD 中搜索 ClusterConfiguration。有关更多信息,请参见启用可插拔组件。
备注 更改值之后,需要等待配置更新完成,然后继续进行后续操作。
卸载 KubeSphere 应用商店
将 CRD ClusterConfiguration 配置文件中 ks-installer 参数的 openpitrix.store.enabled 字段的值从 true 改为 false。
卸载 KubeSphere DevOps
- 卸载 DevOps:
helm uninstall -n kubesphere-devops-system devops
kubectl patch -n kubesphere-system cc ks-installer --type=json -p='[{"op": "remove", "path": "/status/devops"}]'
kubectl patch -n kubesphere-system cc ks-installer --type=json -p='[{"op": "replace", "path": "/spec/devops/enabled", "value": false}]'
- 删除 DevOps 资源:
# 删除所有 DevOps 相关资源
for devops_crd in $(kubectl get crd -o=jsonpath='{range .items[*]}{.metadata.name}{"\n"}{end}' | grep "devops.kubesphere.io"); do
for ns in $(kubectl get ns -ojsonpath='{.items..metadata.name}'); do
for devops_res in $(kubectl get $devops_crd -n $ns -oname); do
kubectl patch $devops_res -n $ns -p '{"metadata":{"finalizers":[]}}' --type=merge
done
done
done
# 删除所有 DevOps CRD
kubectl get crd -o=jsonpath='{range .items[*]}{.metadata.name}{"\n"}{end}' | grep "devops.kubesphere.io" | xargs -I crd_name kubectl delete crd crd_name
# 删除 DevOps 命名空间
kubectl delete namespace kubesphere-devops-system
卸载 KubeSphere 日志系统
- 将 CRD
ClusterConfiguration配置文件中ks-installer参数的logging.enabled字段的值从true改为false。 - 仅禁用日志收集:
kubectl delete inputs.logging.kubesphere.io -n kubesphere-logging-system tail
备注 运行此命令后,默认情况下仍可查看 Kubernetes 提供的容器最近日志。但是,容器历史记录日志将被清除,您无法再浏览它们。
- 卸载包括 Elasticsearch 的日志系统,请执行以下操作:
kubectl delete crd fluentbitconfigs.logging.kubesphere.io
kubectl delete crd fluentbits.logging.kubesphere.io
kubectl delete crd inputs.logging.kubesphere.io
kubectl delete crd outputs.logging.kubesphere.io
kubectl delete crd parsers.logging.kubesphere.io
kubectl delete deployments.apps -n kubesphere-logging-system fluentbit-operator
helm uninstall elasticsearch-logging --namespace kubesphere-logging-system
警告 此操作可能导致审计、事件和服务网格的异常。
- 运行以下命令:
kubectl delete deployment logsidecar-injector-deploy -n kubesphere-logging-system
kubectl delete ns kubesphere-logging-system
卸载 KubeSphere 事件系统
- 将 CRD
ClusterConfiguration配置文件中ks-installer参数的events.enabled字段的值从true改为false。 - 运行以下命令:
helm delete ks-events -n kubesphere-logging-system
卸载 KubeSphere 告警系统
- 将 CRD
ClusterConfiguration配置文件中ks-installer参数的alerting.enabled字段的值从true改为false。 - 运行以下命令:
kubectl -n kubesphere-monitoring-system delete thanosruler kubesphere
备注 KubeSphere 3.2.1 通知系统为默认安装,您无需卸载。
卸载 KubeSphere 审计
- 将 CRD ClusterConfiguration 配置文件中 ks-installer 参数的 auditing.enabled 字段的值从 true 改为 false。
- 运行以下命令:
helm uninstall kube-auditing -n kubesphere-logging-system
kubectl delete crd rules.auditing.kubesphere.io
kubectl delete crd webhooks.auditing.kubesphere.io
卸载 KubeSphere 服务网格
- 将 CRD
ClusterConfiguration配置文件中ks-installer参数的servicemesh.enabled字段的值从true改为false。 - 运行以下命令:
curl -L https://istio.io/downloadIstio | sh -
istioctl x uninstall --purge
kubectl -n istio-system delete kiali kiali
helm -n istio-system delete kiali-operator
kubectl -n istio-system delete jaeger jaeger
helm -n istio-system delete jaeger-operator
卸载网络策略
对于 NetworkPolicy 组件,禁用它不需要卸载组件,因为其控制器位于 ks-controller-manager 中。如果想要将其从 KubeSphere 控制台中移除,将 CRD ClusterConfiguration 配置文件中参数 ks-installer 中 network.networkpolicy.enabled 的值从 true 改为 false。
卸载 Metrics Server
- 将 CRD
ClusterConfiguration配置文件中参数ks-installer中metrics_server.enabled的值从true改为false。 - 运行以下命令:
kubectl delete apiservice v1beta1.metrics.k8s.io
kubectl -n kube-system delete service metrics-server
kubectl -n kube-system delete deployment metrics-server
卸载服务拓扑图
- 将 CRD
ClusterConfiguration配置文件中参数ks-installer中network.topology.type的值从weave-scope改为none。 - 运行以下命令:
kubectl delete ns weave
卸载容器组 IP 池
将 CRD ClusterConfiguration 配置文件中参数 ks-installer 中 network.ippool.type 的值从 calico 改为 none。
五、集群管理
节点管理
Kubernetes 将容器放入容器组(Pod)中并在节点上运行,从而运行工作负载。取决于具体的集群环境,节点可以是虚拟机,也可以是物理机。每个节点都包含运行容器组所需的服务,这些服务由控制平面管理。
本教程介绍集群管理员可查看的集群节点信息和可执行的操作。
准备工作
您需要一个被授予集群管理权限的用户。例如,您可以直接用 admin 用户登录控制台,或创建一个具有集群管理权限的角色然后将此角色授予一个用户。
节点状态
只有集群管理员可以访问集群节点。由于一些节点指标对集群非常重要,集群管理员应监控这些指标并确保节点可用。请按照以下步骤查看节点状态。
- 点击左上角的平台管理,然后选择集群管理。
- 如果您已启用了
多集群功能并已导入了成员集群,您可以选择一个特定集群以查看其节点信息。如果尚未启用该功能,请直接进行下一步。 - 在左侧导航栏中选择
节点下的集群节点,查看节点的状态详情。
- 名称:节点的名称和子网 IP 地址。
- 状态:节点的当前状态,标识节点是否可用。
- 角色:节点的角色,标识节点是工作节点还是主节点。
- CPU 用量:节点的实时 CPU 用量。
- 内存用量:节点的实时内存用量。
- 容器组:节点的实时容器组用量。
- 已分配 CPU:该指标根据节点上容器组的总 CPU 请求数计算得出。它表示节点上为工作负载预留的 CPU 资源。工作负载实际正在使用 CPU 资源可能低于该数值。该指标对于 Kubernetes 调度器 (kube-scheduler) 非常重要。在大多数情况下,调度器在调度容器组时会偏向配得 CPU 资源较少的节点。有关更多信息,请参阅为容器管理资源。
- 已分配内存:该指标根据节点上容器组的总内存请求计算得出。它表示节点上为工作负载预留的内存资源。工作负载实际正在使用内存资源可能低于该数值。
备注 在大多数情况下,CPU 和已分配 CPU 的数值不同,内存和已分配内存的数值也不同,这是正常现象。集群管理员需要同时关注一对指标。最佳实践是根据节点的实际使用情况为每个节点设置资源请求和限制。资源分配不足可能导致集群资源利用率过低,而过度分配资源可能导致集群压力过大从而处于不健康状态。
节点管理
点击列表中的一个节点打开节点详情页面。
- 停止调度/启用调度:您可以在节点重启或维护期间将节点标记为不可调度。Kubernetes 调度器不会将新容器组调度到标记为不可调度的节点。但这不会影响节点上现有工作负载。在 KubeSphere 中,您可以点击节点详情页面的停止调度将节点标记为不可调度。再次点击此按钮(启用调度)可将节点标记为可调度。
- 标签:您可以利用节点标签将容器组分配给特定节点。首先标记节点(例如,用 node-role.kubernetes.io/gpu-node 标记 GPU 节点),然后在创建工作负载时在高级设置中添加此标签,从而使容器组在 GPU 节点上运行。要添加节点标签,请点击更多操作,然后选择编辑标签。
- 污点:污点允许节点排斥一些容器组。您可以在节点详情页面添加或删除节点污点。要添加或删除污点,请点击更多操作,然后从下拉菜单中选择编辑污点。
备注 请谨慎添加污点,因为它们可能会导致意外行为从而导致服务不可用。有关更多信息,请参阅污点和容忍度。
添加和删除节点
当前版本不支持通过 KubeSphere 控制台添加或删除节点。您可以使用 KubeKey 来进行此类操作。有关更多信息,请参阅添加新节点和删除节点。
集群状态监控
KubeSphere 支持对集群 CPU、内存、网络和磁盘等资源的相关指标进行监控。在集群状态页面,您可以查看历史监控数据并根据不同资源的使用率对节点进行排序。
准备工作
您需要一个被授予集群管理权限的用户。例如,您可以直接用 admin 用户登录控制台,或创建一个具有集群管理权限的角色然后将此角色授予一个用户。
集群状态监控
- 点击左上角的平台管理,然后选择集群管理。
- 如果您已启用了多集群功能并已导入了成员集群,您可以选择一个特定集群以查看其应用程序资源。如果尚未启用该功能,请直接进行下一步。
- 在左侧导航栏选择监控告警下的集群状态以查看集群状态概览,包括集群节点状态、组件状态、集群资源用量、etcd 监控和服务组件监控。
集群节点状态
- 集群节点状态显示在线节点和所有节点的数量。您可以点击节点在线状态跳转到集群节点页面以查看所有节点的实时资源使用情况。
- 在集群节点页面,点击节点名称可打开运行状态页面查看资源用量,已分配资源和健康状态。
- 点击监控选项卡,可以查看节点在特定时间范围内的各种运行指标,包括 CPU 用量、CPU 平均负载、内存用量、磁盘用量、Inode 用量、IOPS、磁盘吞吐和网络带宽。
提示 您可以在右上角的下拉列表中自定义时间范围查看历史数据。
组件状态
KubeSphere 监控集群中各种服务组件的健康状态。当关键组件发生故障时,系统可能会变得不可用。KubeSphere 的监控机制确保平台可以在组件出现故障时将所有问题通知租户,以便快速定位问题并采取相应的措施。
- 在集群状态页面,点击组件状态区域的组件可查看其状态。
- 系统组件页面列出了所有的组件。标记为绿色的组件是正常运行的组件,标记为橙色的组件存在问题,需要特别关注。
提示 标记为橙色的组件可能会由于各种原因在一段时间后变为绿色,例如重试拉取镜像或重新创建实例。您可以点击一个组件查看其服务详情。
集群资源用量
集群资源用量显示集群中所有节点的 CPU 用量、内存用量、磁盘用量和容器组数量。您可以点击左侧的饼图切换指标。右侧的曲线图显示一段时间内指示的变化趋势。
物理资源监控
您可以利用物理资源监控页面提供的数据更好地掌控物理资源状态,并建立正常资源和集群性能的标准。KubeSphere 允许用户查看最近 7 天的集群监控数据,包括 CPU 用量、内存用量、CPU 平均负载(1 分钟/5 分钟/15 分钟)、磁盘用量、Inode 用量、磁盘吞吐(读写)、IOPS(读写)、网络带宽和容器组状态。您可以在 KubeSphere 中自定义时间范围和时间间隔以查看物理资源的历史监控数据。以下简要介绍每个监控指标。
CPU 用量
CPU 用量显示一段时间内 CPU 资源的用量。如果某一时间段的 CPU 用量急剧上升,您首先需要定位占用 CPU 资源最多的进程。例如,Java 应用程序代码中的内存泄漏或无限循环可能会导致 CPU 用量急剧上升。
内存用量
内存是机器上的重要组件之一,是与 CPU 通信的桥梁。因此,内存对机器的性能有很大影响。当程序运行时,数据加载、线程并发和 I/O 缓冲都依赖于内存。可用内存的大小决定了程序能否正常运行以及如何运行。内存使用情况反映了集群内存资源的整体用量,显示为特定时刻内存占用的百分比。
CPU 平均负载
CPU 平均负载是单位时间内系统中处于可运行状态和非中断状态的平均进程数(亦即活动进程的平均数量)。CPU 平均负载和 CPU 利用率之间没有直接关系。理想情况下,平均负载应该等于 CPU 的数量。因此,在查看平均负载时,需要考虑 CPU 的数量。只有当平均负载大于 CPU 数量时,系统才会超载。
KubeSphere 为用户提供了 1 分钟、5 分钟和 15 分钟三种不同的平均负载。通常情况下,建议您比较这三种数据以全面了解平均负载情况。
- 如果在一定时间范围内 1 分钟、5 分钟和 15 分钟的曲线相似,则表明集群的 CPU 负载相对稳定。
- 如果某一时间范围或某一特定时间点 1 分钟的数值远大于 15 分钟的数值,则表明最近 1 分钟的负载在增加,需要继续观察。一旦 1 分钟的数值超过 CPU 数量,系统可能出现超载,您需要进一步分析问题的根源。
- 如果某一时间范围或某一特定时间点 1 分钟的数值远小于 15 分钟的数值,则表明系统在最近 1 分钟内负载在降低,在前 15 分钟内出现了较高的负载。
磁盘用量
KubeSphere 的工作负载(例如有状态副本集和守护进程集)都依赖于持久卷。某些组件和服务也需要持久卷。这种后端存储依赖于磁盘,例如块存储或网络共享存储。因此,实时的磁盘用量监控环境对确保数据的高可靠性尤为重要。
在 Linux 系统的日常管理中,平台管理员可能会遇到磁盘空间不足导致数据丢失甚至系统崩溃的情况。作为集群管理的重要组成部分,平台管理员需要密切关注系统的磁盘使用情况,并确保文件系统不会被用尽或滥用。通过监控磁盘使用的历史数据,您可以评估特定时间范围内磁盘的使用情况。在磁盘用量较高的情况下,您可以通过清理不必要的镜像或容器来释放磁盘空间。
Inode 用量
每个文件都有一个 inode,用于存储文件的创建者和创建日期等元信息。inode 也会占用磁盘空间,众多的小缓存文件很容易导致 inode 资源耗尽。此外,在 inode 已用完但磁盘未满的情况下,也无法在磁盘上创建新文件。
在 KubeSphere 中,对 inode 使用率的监控可以帮助您清楚地了解集群 inode 的使用率,从而提前检测到此类情况。该机制提示用户及时清理临时文件,防止集群因 inode 耗尽而无法工作。
磁盘吞吐
磁盘吞吐和 IOPS 监控是磁盘监控不可或缺的一部分,可帮助集群管理员调整数据布局和其他管理活动以优化集群整体性能。磁盘吞吐量是指磁盘传输数据流(包括读写数据)的速度,单位为 MB/s。当传输大块非连续数据时,该指标具有重要的参考意义。
IOPS
IOPS 表示每秒读写操作数。具体来说,磁盘的 IOPS 是每秒连续读写的总和。当传输小块非连续数据时,该指示器具有重要的参考意义。
网络带宽
网络带宽是网卡每秒接收或发送数据的能力,单位为 Mbps。
容器组状态
容器组状态显示不同状态的容器组的总数,包括运行中、已完成和异常状态。标记为已完成的容器组通常为任务(Job)或定时任务(CronJob)。标记为异常的容器组需要特别注意。
etcd 监控
etcd 监控可以帮助您更好地利用 etcd,特别用于是定位性能问题。etcd 服务提供了原生的指标接口。KubeSphere 监控系统提供了高度图形化和响应性强的仪表板,用于显示原生数据。
| 指标 | 描述 |
|---|---|
| 服务状态 | - 是否有 Leader 表示成员是否有 Leader。如果成员没有 Leader,则成员完全不可用。如果集群中的所有成员都没有任何 Leader,则整个集群完全不可用。- 1 小时内 Leader 变更次数表示集群成员观察到的 1 小时内 Leader 变更总次数。频繁变更 Leader 将显著影响 etcd 性能,同时这还表明 Leader 可能由于网络连接问题或 etcd 集群负载过高而不稳定。 |
| 库大小 | etcd 的底层数据库大小,单位为 MiB。图表中显示的是 etcd 的每个成员数据库的平均大小。 |
| 客户端流量 | 包括发送到 gRPC 客户端的总流量和从 gRPC 客户端接收的总流量。有关该指标的更多信息,请参阅 etcd Network。 |
| gRPC 流式消息 | 服务器端的 gRPC 流消息接收速率和发送速率,反映集群内是否正在进行大规模的数据读写操作。有关该指标的更多信息,请参阅 go-grpc-prometheus。 |
| WAL 日志同步时间 | WAL 调用 fsync 的延迟。在应用日志条目之前,etcd 会在持久化日志条目到磁盘时调用 wal_fsync。有关该指标的更多信息,请参阅 etcd Disk。 |
| 库同步时间 | 后端调用提交延迟的分布。当 etcd 将其最新的增量快照提交到磁盘时,会调用 backend_commit。需要注意的是,磁盘操作延迟较大(WAL 日志同步时间或库同步时间较长)通常表示磁盘存在问题,这可能会导致请求延迟过高或集群不稳定。有关该指标的详细信息,请参阅 etcd Disk。 |
| Raft 提议 | - 提议提交速率记录提交的协商一致提议的速率。如果集群运行状况良好,则该指标应随着时间的推移而增加。etcd 集群的几个健康成员可以同时具有不同的一般提议。单个成员与其 Leader 之间的持续较大滞后表示该成员缓慢或不健康。- 提议应用速率记录协商一致提议的总应用率。etcd 服务器异步地应用每个提交的提议。提议提交速率和提议应用速率的差异应该很小(即使在高负载下也只有几千)。如果它们之间的差异持续增大,则表明 etcd 服务器过载。当使用大范围查询或大量 txn 操作等大规模查询时,可能会出现这种情况。- 提议失败速率记录提议失败的总速率。这通常与两个问题有关:与 Leader 选举相关的临时失败或由于集群成员数目达不到规定数目而导致的长时间停机。- 排队提议数记录当前待处理提议的数量。待处理提议的增加表明客户端负载较高或成员无法提交提议。 目前,仪表板上显示的数据是 etcd 成员的平均数值。有关这些指标的详细信息,请参阅 etcd Server。 |
API Server 监控
API Server 是 Kubernetes 集群中所有组件交互的中枢。下表列出了 API Server 的主要监控指标。
| 指标 | 描述 |
|---|---|
| 请求延迟 | 资源请求响应延迟,单位为毫秒。该指标按照 HTTP 请求方法进行分类。 |
| 每秒请求次数 | kube-apiserver 每秒接受的请求数。 |
调度器监控
调度器监控新建容器组的 Kubernetes API,并决定这些新容器组运行在哪些节点上。调度器根据收集资源的可用性和容器组的资源需求等数据进行决策。监控调度延迟的数据可确保您及时了解调度器的任何延迟。
| 指标 | 描述 |
|---|---|
| 调度次数 | 包括调度成功、错误和失败的次数。 |
| 调度频率 | 包括调度成功、错误和失败的频率。 |
| 调度延迟 | 端到端调度延迟,即调度算法延迟和绑定延迟之和。 |
节点用量排行
您可以按 CPU 用量、CPU 平均负载、内存用量、本地存储用量、Inode 用量和容器组用量等指标对节点进行升序和降序排序。您可以利用这一功能快速发现潜在问题和节点资源不足的情况。
应用资源监控
除了在物理资源级别监控数据外,集群管理员还需要密切跟踪整个平台上的应用资源,例如项目和 DevOps 项目的数量,以及特定类型的工作负载和服务的数量。应用资源提供了平台的资源使用情况和应用级趋势的汇总信息。
准备工作
您需要一个被授予集群管理权限的用户。例如,您可以直接用 admin 用户登录控制台,或创建一个具有集群管理权限的角色然后将此角色授予一个用户。
使用情况
- 点击左上角的平台管理,然后选择集群管理。
- 如果您已启用了多集群功能并已导入了成员集群,您可以选择一个集群以查看其应用程序资源。如果尚未启用该功能,请直接进行下一步。
- 在左侧导航栏选择监控告警下的应用资源以查看应用资源概览,包括集群中所有资源使用情况的汇总信息。
- 集群资源用量和应用资源用量提供最近 7 天的监控数据,并支持自定义时间范围查询。
- 点击特定资源以查看特定时间段内的使用详情和趋势,例如集群资源用量下的 CPU。在详情页面,您可以按项目查看特定的监控数据,以及自定义时间范围查看资源的确切使用情况。
用量排行
用量排行支持按照资源使用情况对项目进行排序,帮助平台管理员了解当前集群中每个项目的资源使用情况,包括 CPU 用量、内存用量、容器组数量、网络流出速率和网络流入速率。您可以选择下拉列表中的任一指标对项目按升序或降序进行排序。此功能可以帮助您快速定位大量消耗 CPU 或内存资源的应用程序(容器组)。
持久卷和存储类型
本教程对 PV、PVC 以及存储类型 (Storage Class) 的基本概念进行说明,并演示集群管理员如何管理 KubeSphere 中的存储类型和持久化存储卷。
介绍
PersistentVolume (PV) 是集群中的一块存储,可以由管理员事先供应,或者使用存储类型来动态供应。PV 是像存储卷 (Volume) 一样的存储卷插件,但是它的生命周期独立于任何使用该 PV 的容器组。PV 可以静态供应或动态供应。
PersistentVolumeClaim (PVC) 是用户对存储的请求。它与容器组类似,容器组会消耗节点资源,而 PVC 消耗 PV 资源。
KubeSphere 支持基于存储类型的动态卷供应,以创建 PV。
存储类型是管理员描述其提供的存储类型的一种方式。不同的类型可能会映射到不同的服务质量等级或备份策略,或由集群管理员制定的任意策略。每个存储类型都有一个 Provisioner,用于决定使用哪个存储卷插件来供应 PV。该字段必须指定。
下表总结了各种 Provisioner(存储系统)常用的存储卷插件。
| 类型 | 描述信息 |
|---|---|
| In-tree | 内置并作为 Kubernetes 的一部分运行,例如 RBD 和 GlusterFS。有关此类插件的更多信息,请参见 Provisioner。 |
| External-provisioner | 独立于 Kubernetes 部署,但运行上类似于树内 (in-tree) 插件,例如 NFS 客户端。有关此类插件的更多信息,请参见 External Storage。 |
| CSI | 容器存储接口,一种将存储资源暴露给 CO(例如 Kubernetes)上的工作负载的标准,例如 QingCloud-CSI 和 Ceph-CSI。有关此类插件的更多信息,请参见 Drivers。 |
准备工作
您需要一个拥有集群管理权限的帐户。例如,您可以直接以 admin 身份登录控制台,或者创建一个拥有该权限的新角色并将它分配至一个用户。
管理存储类型
- 点击左上角的平台管理,然后选择集群管理。
- 如果您启用了多集群功能并导入了成员集群,可以选择一个特定集群。如果您未启用该功能,请直接参考下一步。
- 在集群管理页面,您可以在存储下的存储类型中创建、更新和删除存储类型。
- 要创建一个存储类型,请点击创建,在弹出窗口中输入基本信息。完成后,点击下一步。
- 在 KubeSphere 中,您可以直接为 QingCloud-CSI、GlusterFS 和 Ceph RBD 创建存储类型。或者,您也可以根据需求为其他存储系统创建自定义存储类型。请选择一个类型,然后点击下一步。
常用设置
有些设置在存储类型之间常用且共享。您可以在控制台上的仪表板参数中找到这些设置,存储类型清单文件中也通过字段或注解加以显示。您可以在右上角点击编辑 YAML,查看 YAML 格式的配置文件。下表是对 KubeSphere 中一些常用字段的参数说明。
| 参数 | 描述 |
|---|---|
| 存储卷扩容 | 在清单文件中由 allowVolumeExpansion 指定。若设置为 true,PV 则被配置为可扩容。有关更多信息,请参见允许卷扩展。 |
| 回收机制 | 在清单文件中由 reclaimPolicy 指定。可设置为 Delete 或 Retain(默认)。有关更多信息,请参见回收策略。 |
| 存储系统 | 在清单文件中由 provisioner 指定。它决定使用什么存储卷插件来供应 PV。有关更多信息,请参见 Provisioner。 |
| 访问模式 | 在清单文件中由 metadata.annotations[storageclass.kubesphere.io/supported-access-modes] 指定。它会向 KubeSphere 表明支持的访问模式。 |
| 存储卷绑定模式 | 在清单文件中由 volumeBindingMode 指定。它决定使用何种绑定模式。延迟绑定即存储卷创建后,当使用此存储卷的容器组被创建时,此存储卷绑定到一个存储卷实例。立即绑定即存储卷创建后,立即绑定到一个存储卷实例。 |
对于其他设置,您需要为不同的存储插件提供不同的信息,它们都显示在清单文件的 parameters 字段下。下面将进行详细说明,您也可以参考 Kubernetes 官方文档的参数部分。
QingCloud CSI
QingCloud CSI 是 Kubernetes 上的 CSI 插件,供青云QingCloud 存储服务使用。KubeSphere 控制台上可以创建 QingCloud CSI 的存储类型。
准备工作
- QingCloud CSI 在青云QingCloud 的公有云和私有云上均可使用。因此,请确保将 KubeSphere 安装至二者之一,以便可以使用云存储服务。
- KubeSphere 集群上已经安装 QingCloud CSI 插件。有关更多信息,请参见安装 QingCloud CSI。
设置
| 参数 | 描述信息 |
|---|---|
| 类型 | 在青云云平台中,0 代表性能型硬盘;2 代表容量型硬盘;3 代表超高性能型硬盘;5 代表企业级分布式 SAN(NeonSAN)型硬盘;100 代表基础型硬盘;200 代表 SSD 企业型硬盘。 |
| 容量上限 | 存储卷容量上限。 |
| 增量值 | 存储卷容量增量。 |
| 容量下限 | 存储卷容量下限。 |
| 文件系统类型 | 支持 ext3、ext4 和 XFS。默认类型为 ext4。 |
| 标签 | 为存储卷添加标签。使用半角逗号(,)分隔多个标签。 |
GlusterFS
GlusterFS 是 Kubernetes 上的一种树内存储插件,即您不需要额外安装存储卷插件。
准备工作
已经安装 GlusterFS 存储系统。有关更多信息,请参见 GlusterFS 安装文档。
设置
| 参数 | 描述 |
|---|---|
| REST URL | 供应存储卷的 Heketi REST URL,例如,:。 |
| 集群 ID | Gluster 集群 ID。 |
| 启用 REST 认证 | Gluster 启用对 REST 服务器的认证。 |
| REST 用户 | vGluster REST 服务或 Heketi 服务的用户名。 |
| 密钥所属项目 | Heketi 用户密钥的所属项目。 |
| 密钥名称 | Heketi 用户密钥的名称。 |
| GID 最小值 | v存储卷的 GID 最小值。 |
| GID 最大值 | 存储卷的 GID 最大值。 |
| 存储卷类型 | v存储卷的类型。该值可为 none,replicate:<副本数>,或 disperse:<数据>:<冗余数>。如果未设置该值,则默认存储卷类型为 replicate:3。 |
Ceph RBD
Ceph RBD 也是 Kubernetes 上的一种树内存储插件,即 Kubernetes 中已经安装该存储卷插件,但您必须在创建 Ceph RBD 的存储类型之前安装其存储服务器。
由于 hyperkube 镜像自 1.17 版本开始已被弃用,树内 Ceph RBD 可能无法在不使用 hyperkube 的 Kubernetes 上运行。不过,您可以使用 RBD Provisioner 作为替代,它的格式与树内 Ceph RBD 相同。唯一不同的参数是 provisioner(即 KubeSphere 控制台上的存储系统)。如果您想使用 RBD Provisioner,provisioner 的值必须为 ceph.com/rbd(在存储系统中输入该值,如下图所示)。如果您使用树内 Ceph RBD,该值必须为 kubernetes.io/rbd。
准备工作
- 已经安装 Ceph 服务器。有关更多信息,请参见 Ceph 安装文档。
- 如果您选择使用 RBD Provisioner,请安装插件。社区开发者提供了 RBD Provisioner 的 Chart,您可以通过 Helm 用这些 Chart 安装 RBD Provisioner。
设置
| 参数 | 描述 |
|---|---|
| monitors | Ceph 集群 Monitors 的 IP 地址。 |
| adminId | Ceph 集群能够创建卷的用户 ID。 |
| adminSecretName | adminId 的密钥名称。 |
| adminSecretNamespace | adminSecret 所在的项目。 |
| pool | Ceph RBD 的 Pool 名称。 |
| userId | Ceph 集群能够挂载卷的用户 ID。 |
| userSecretName | userId 的密钥名称。 |
| userSecretNamespace | userSecret 所在的项目。 |
| 文件系统类型 | 存储卷的文件系统类型。 |
| imageFormat | Ceph 卷的选项。该值可为 1 或 2,选择 2 后需要填写 imageFeatures。 |
| imageFeatures | Ceph 集群的额外功能。仅当设置 imageFormat 为 2 时,才需要填写该值。 |
自定义存储类型
如果 KubeSphere 不直接支持您的存储系统,您可以为存储系统创建自定义存储类型。下面的示例向您演示了如何在 KubeSphere 控制台上为 NFS 创建存储类型。
NFS 介绍
NFS(网络文件系统)广泛用于带有 NFS-Client(External-Provisioner 存储卷插件)的 Kubernetes。您可以点击自定义来创建 NFS-Client 的存储类型。
备注 不建议您在生产环境中使用 NFS 存储(尤其是在 Kubernetes 1.20 或以上版本),这可能会引起 failed to obtain lock 和 input/output error 等问题,从而导致容器组 CrashLoopBackOff。此外,部分应用不兼容 NFS,例如 Prometheus 等。
准备工作
- 有一个可用的 NFS 服务器。
- 已经安装存储卷插件 NFS-Client。社区开发者提供了 NFS-Client 的 Chart,您可以通过 Helm 用这些 Chart 安装 NFS-Client。
常用设置
| 参数 | 描述信息 |
|---|---|
| 存储卷扩容 | 在清单文件中由 allowVolumeExpansion 指定。选择否。 |
| 回收机制 | 在清单文件中由 reclaimPolicy 指定。 |
| 存储系统 | 在清单文件中由 provisioner 指定。如果您使用 NFS-Client 的 Chart 来安装存储类型,可以设为 cluster.local/nfs-client-nfs-client-provisioner。 |
| 访问模式 | 在清单文件中由 .metadata.annotations.storageclass.kubesphere.io/supported-access-modes 指定。默认 ReadWriteOnce、ReadOnlyMany 和 ReadWriteMany 全选。 |
| 存储卷绑定模式 | 在清单文件中由 volumeBindingMode 指定。它决定使用何种绑定模式。延迟绑定即存储卷创建后,当使用此存储卷的容器组被创建时,此存储卷绑定到一个存储卷实例。立即绑定即存储卷创建后,立即绑定到一个存储卷实例。 |
参数
| 键 | 描述信息 | 值 |
|---|---|---|
| archiveOnDelete | 删除时存档 | PVC |
存储类型详情页
创建存储类型后,点击此存储类型的名称前往其详情页。在详情页点击编辑 YAML 来编辑此存储类型的清单文件,或点击更多操作并在下拉菜单中选择一项操作:
- 设为默认存储类型:将此存储类型设为集群的默认存储类型。一个 KubeSphere 集群中仅允许设置一个默认存储类型。
- 存储卷管理:管理存储卷功能,包括:存储卷克隆、存储卷快照、存储卷扩容。开启任意功能前,请联系系统管理员确认存储系统是否支持这些功能。
- 删除:删除此存储类型并返回上一页。
在存储卷页签上,查看与此存储类型相关联的存储卷。
管理存储卷
存储类型创建后,您可以使用它来创建存储卷。您可以在 KubeSphere 控制台上的存储管理下面的存储卷中列示、创建、更新和删除存储卷。有关更多详细信息,请参见存储卷管理。
管理存储卷实例
KubeSphere 中的存储卷即 Kubernetes 中的持久卷声明,存储卷实例即 Kubernetes 中的持久卷。
存储卷实例列表页面
- 以 admin 身份登录 KubeSphere Web 控制台。点击左上角的平台管理,选择集群管理,然后在左侧导航栏点击存储下的存储卷。
- 在存储卷页面,点击存储卷实例页签,查看存储卷实例列表页面。该页面提供以下信息:
- 名称:存储卷实例的名称,在该存储卷实例的清单文件中由 .metadata.name 字段指定。
- 状态:存储卷实例的当前状态,在该存储卷实例的清单文件中由 .status.phase 字段指定,包括:
- 可用:存储卷实例可用,尚未绑定至存储卷。
- 已绑定:存储卷实例已绑定至存储卷。
- 删除中:正在删除存储卷实例。
- 失败:存储卷实例不可用。
- 容量:存储卷实例的容量,在该存储卷实例的清单文件中由 .spec.capacity.storage 字段指定。
- 访问模式:存储卷实例的访问模式,在该存储卷实例的清单文件中由 .spec.accessModes 字段指定,包括:
- RWO:存储卷实例可挂载为单个节点读写。
- ROX:存储卷实例可挂载为多个节点只读。
- RWX:存储卷实例可挂载为多个节点读写。
- 回收策略:存储卷实例的回收策略,在该存储卷实例的清单文件中由 .spec.persistentVolumeReclaimPolicy 字段指定,包括:
- Retain:删除存储卷后,保留该存储卷实例,需要手动回收。
- Delete:删除该存储卷实例,同时从存储卷插件的基础设施中删除所关联的存储设备。
- Recycle:清除存储卷实例上的数据,使该存储卷实例可供新的存储卷使用。
- 创建时间:存储卷实例的创建时间。
- 点击存储卷实例右侧的 并在下拉菜单中选择一项操作:
- 编辑:编辑存储卷实例的 YAML 文件。
- 查看 YAML:查看存储卷实例的 YAML 文件。
- 删除:删除存储卷实例。处于已绑定状态的存储卷实例不可删除。
存储卷实例详情页面
- 点击存储卷实例的名称,进入其详情页面。
- 在详情页面,点击编辑信息以编辑存储卷实例的基本信息。点击更多操作,在下拉菜单中选择一项操作:
查看 YAML:查看存储卷实例的 YAML 文件。删除:删除存储卷实例并返回列表页面。处于已绑定状态的存储卷实例不可删除。
- 点击资源状态页签,查看存储卷实例所绑定的存储卷。
- 点击
元数据页签,查看存储卷实例的标签和注解。 - 点击
事件页签,查看存储卷实例的事件。
六、企业空间管理及角色管理
企业空间概述
企业空间是用来管理项目、DevOps 项目、应用模板和应用仓库的一种逻辑单元。您可以在企业空间中控制资源访问权限,也可以安全地在团队内部分享资源。
最佳的做法是为租户(集群管理员除外)创建新的企业空间。同一名租户可以在多个企业空间中工作,并且多个租户可以通过不同方式访问同一个企业空间。
准备工作
准备一个被授予 workspaces-manager 角色的用户,例如创建企业空间、项目、用户和角色中创建的 ws-manager 帐户。
创建企业空间
- 以
ws-manager身份登录KubeSphere Web控制台。点击左上角的平台管理并选择访问控制。在企业空间页面,点击创建。
备注 列表中已列出默认企业空间 system-workspace,该企业空间包含所有系统项目。
- 对于单节点集群,您需要在基本信息页面,为创建的企业空间输入名称,并从下拉菜单中选择一名企业空间管理员。点击创建。
- 名称:为企业空间设置一个专属名称。
- 别名:该企业空间的另一种名称。
- 管理员:管理该企业空间的用户。
- 描述:企业空间的简短介绍。
对于多节点集群,设置企业空间的基本信息后,点击下一步。在集群设置页面,选择企业空间需要使用的集群,然后点击创建。
- 企业空间创建后将显示在企业空间列表中。
- 点击该企业空间,您可以在概览页面查看企业空间中的资源状态。
删除企业空间
在 KubeSphere 中,可以通过企业空间对项目进行分组管理,企业空间下项目的生命周期会受到企业空间的影响。具体来说,企业空间删除之后,企业空间下的项目及关联的资源也同时会被销毁。
删除企业空间之前,请先确定您是否要解绑部分关键项目。
删除前解绑项目
若要删除企业空间并保留其中的部分项目,删除前请先执行以下命令:
kubectl label ns <namespace> kubesphere.io/workspace- && kubectl patch ns <namespace> -p '{"metadata":{"ownerReferences":[]}}' --type=merge
备注 以上命令会移除与企业空间关联的标签并移除 ownerReferences。之后,您可以将解绑的项目重新分配给新的企业空间。
在控制台上删除企业空间
从企业空间解绑关键项目后,您可以按照以下步骤删除企业空间。
备注 如果您使用 kubectl 删除企业空间资源对象,请务必谨慎操作。
- 在企业空间页面,转到企业空间设置菜单下的基本信息。在基本信息页面,您可以查看该企业空间的基本信息,例如项目数量和成员数量。
备注 在该页面,您可以点击编辑信息更改企业空间的基本信息(企业空间名称无法更改),也可以开启或关闭网络隔离。
- 若要删除企业空间,点击删除企业空间下的删除。在出现的对话框中输入企业空间的名称,然后点击确定。
警告 企业空间删除后将无法恢复,并且企业空间下的资源也同时会被销毁。
企业空间角色和成员管理
准备工作
至少已创建一个企业空间,例如 demo-workspace。您还需要准备一个用户(如 ws-admin),该用户在企业空间级别具有 workspace-admin 角色。有关更多信息,请参见创建企业空间、项目、用户和角色。
备注 实际角色名称的格式:workspace name-role name。例如,在名为 demo-workspace 的企业空间中,角色 admin 的实际角色名称为 demo-workspace-admin。
内置角色
企业空间角色页面列出了以下四个可用的内置角色。创建企业空间时,KubeSphere 会自动创建内置角色,并且内置角色无法进行编辑或删除。您只能查看内置角色的权限或将其分配给用户。
| 名称 | 描述 |
|---|---|
| workspace-viewer | 企业空间观察员,可以查看企业空间中的所有资源。 |
| workspace-self-provisioner | 企业空间普通成员,可以查看企业设置、管理应用模板、创建项目和 DevOps 项目。 |
| workspace-regular | 企业空间普通成员,可以查看企业空间设置。 |
| workspace-admin | 企业空间管理员,可以管理企业空间中的所有资源。 |
若要查看角色所含权限:
- 以 ws-admin 身份登录控制台。在企业空间角色中,点击一个角色(例如,workspace-admin)以查看角色详情。
- 点击授权用户选项卡,查看所有被授予该角色的用户。
创建企业空间角色
- 转到企业空间设置下的企业空间角色。
- 在企业空间角色中,点击创建并设置名称(例如,demo-project-admin)。点击编辑权限继续。
- 在弹出的窗口中,权限归类在不同的功能模块下。在本示例中,点击项目管理,并为该角色选择项目创建、项目管理和项目查看。点击确定完成操作。
备注 依赖于表示当前授权项依赖所列出的授权项,勾选该权限后系统会自动选上所有依赖权限。
- 新创建的角色将在企业空间角色中列出,点击右侧的 以编辑该角色的信息、权限,或删除该角色。
邀请新成员
- 转到企业空间设置下企业空间成员,点击邀请。
- 点击右侧的"+"以邀请一名成员加入企业空间,并为其分配一个角色。
- 将成员加入企业空间后,点击确定。您可以在企业空间成员列表中查看新邀请的成员。
- 若要编辑现有成员的角色或将其从企业空间中移除,点击右侧的":"并选择对应的操作。
企业空间网络隔离
准备工作
- 已经启用网络策略。
- 需要使用拥有
workspace-admin角色的用户。例如,使用在创建企业空间、项目、用户和角色教程中创建的ws-admin用户。
备注 关于网络策略的实现,您可以参考 `KubeSphere NetworkPolicy`。
开启或关闭企业空间网络隔离
企业空间网络隔离默认关闭。您可以在企业空间设置下的基本信息页面开启网络隔离。
备注 当网络隔离开启时,默认允许出站流量,而不同企业空间的进站流量将被拒绝。如果您需要自定义网络策略,则需要开启项目网络隔离并在项目设置中添加网络策略。
您也可以在基本信息页面关闭网络隔离。
最佳做法
要确保企业空间中的所有容器组都安全,一个最佳做法是开启企业空间网络隔离。
当网络隔离开启时,其他企业空间无法访问该企业空间。如果企业空间的默认网络隔离无法满足您的需求,请开启项目网络隔离并自定义您的项目网络策略。
项目配额
KubeSphere 使用预留(Request)和限制(Limit)来控制项目中的资源(例如 CPU 和内存)使用情况,在 Kubernetes 中也称为资源配额。请求确保项目能够获得其所需的资源,因为这些资源已经得到明确保障和预留。相反地,限制确保项目不能使用超过特定值的资源。
除了 CPU 和内存,您还可以单独为其他对象设置资源配额,例如项目中的容器组、部署、任务、服务和配置字典。
准备工作
您需要有一个可用的企业空间、一个项目和一个用户 (ws-admin)。该用户必须在企业空间层级拥有 admin 角色。有关更多信息,请参见创建企业空间、项目、用户和角色。
备注 如果使用 project-admin 用户(该用户在项目层级拥有 admin 角色),您也可以为新项目(即其配额尚未设置)设置项目配额。不过,项目配额设置完成之后,project-admin 无法更改配额。一般情况下,ws-admin 负责为项目设置限制和请求。project-admin 负责为项目中的容器设置限制范围。
设置项目配额
- 以 ws-admin 身份登录控制台,进入一个项目。如果该项目是新创建的项目,您可以在概览页面看到项目配额尚未设置。点击编辑配额来配置配额。
- 在弹出对话框中,您可以看到 KubeSphere 默认不为项目设置任何请求或限制。要设置请求和限制来控制 CPU 和内存资源,请将滑块移动到期望的值或者直接输入数字。字段留空意味着您不设置任何请求或限制。
备注 限制必须大于请求。
- 要为其他资源设置配额,在项目资源配额下点击添加,选择一个资源或输入资源名称并设置配额。
- 点击确定完成配额设置。
- 在项目设置下的基本信息页面,您可以查看该项目的所有资源配额。
- 要更改项目配额,请在基本信息页面点击编辑项目,然后选择编辑项目配额。
备注 对于多集群项目,管理项目下拉菜单中不会显示编辑配额选项。若要为多集群项目设置配额,前往项目设置下的项目配额,并点击编辑配额。请注意,由于多集群项目跨集群运行,您可以为多集群项目针对不同集群分别设置资源配额。
- 在项目配额页面更改项目配额,然后点击确定。
企业空间配额
企业空间配额用于管理企业空间中所有项目和 DevOps 项目的总资源用量。企业空间配额与项目配额相似,也包含 CPU 和内存的预留(Request)和限制(Limit)。预留确保企业空间中的项目能够获得其所需的资源,因为这些资源已经得到明确保障和预留。相反,限制则确保企业空间中的所有项目的资源用量不能超过特定数值。
在多集群架构中,由于您需要将一个或多个集群分配到企业空间中,您可以设置该企业空间在不同集群上的资源用量。
本教程演示如何管理企业空间中的资源配额。
准备工作
您需要准备一个可用的企业空间和一个用户 (ws-manager)。该用户必须在平台层级具有 workspaces-manager 角色。有关更多信息,请参阅创建企业空间、项目、用户和角色。
设置企业空间配额
- 使用 ws-manager 用户登录 KubeSphere Web 控制台,进入企业空间。
- 在企业空间设置下,选择企业空间配额。
- 企业空间配额页面列有分配到该企业空间的全部可用集群,以及各集群的 CPU 限额、CPU 需求、内存限额和内存需求。
- 在列表右侧点击编辑配额即可查看企业空间配额信息。默认情况下,KubeSphere 不为企业空间设置任何资源预留或资源限制。如需设置资源预留或资源限制来管理 CPU 和内存资源,您可以移动 至期望数值或直接输入期望数值。将字段设为空值表示不对资源进行预留或限制。
备注 资源预留不能超过资源限制。
- 配额设置完成后,点击确定。
部门管理
企业空间中的部门是用来管理权限的逻辑单元。您可以在部门中设置企业空间角色、多个项目角色以及多个 DevOps 项目角色,还可以将用户分配到部门中以批量管理用户权限。
准备工作
- 您需要创建
一个企业空间和一个用户,该用户需在该企业空间中具有workspace-admin角色。本文档以 demo-ws 企业空间和 ws-admin 用户为例。 - 如需在一个部门中设置项目角色或者 DevOps 项目角色,则需要在该企业空间中
创建至少一个项目或一个 DevOps 项目。
创建部门
- 以 ws-admin 用户登录 KubeSphere Web 控制台并进入 demo-ws 企业空间。
- 在左侧导航栏选择企业空间设置下的部门管理,点击右侧的设置部门。
- 在设置部门对话框中,设置以下参数,然后点击确定创建部门。
备注 如果企业空间中已经创建过部门,您可以点击创建部门为该企业空间添加更多部门。 您可以在每个部门中创建多个部门和多个子部门。如需创建子部门,在左侧部门树中选择一个部门,然后点击右侧的创建部门。
- 名称:为部门设置一个名称。
- 别名:为部门设置一个别名。
- 企业空间角色:当前企业空间中所有部门成员的角色。
- 项目角色:一个项目中所有部门成员的角色。您可以点击添加项目来指定多个项目角色。每个项目只能指定一个角色。
- DevOps 项目角色:一个 DevOps 项目中所有部门成员的角色。您可以点击添加 DevOps 项目来指定多个 DevOps 项目角色。每个 DevOps 项目只能指定一个角色。
- 部门创建完成后,点击确定,然后点击关闭。在部门管理页面,可以在左侧的部门树中看到已创建的部门。
分配用户至部门
- 在部门管理页面,选择左侧部门树中的一个部门,点击右侧的未分配。
- 在用户列表中,点击用户右侧的 ,对出现的提示消息点击确定,以将用户分配到该部门。
备注 1. 如果部门提供的权限与用户的现有权限重叠,则会为用户添加新的权限。用户的现有权限不受影响。 2. 分配到某个部门的用户可以根据与该部门关联的企业空间角色、项目角色和 DevOps 项目角色来执行操作,而无需被邀请到企业空间、项目和 DevOps 项目中。
从部门中移除用户
- 在部门管理页面,选择左侧部门树中的一个部门,然后点击右侧的已分配。
- 在已分配用户列表中,点击用户右侧的 ,在出现的对话框中输入相应的用户名,然后点击确定来移除用户。
删除和编辑部门
- 在部门管理页面,点击设置部门。
- 在设置部门对话框的左侧,点击需要编辑或删除部门的上级部门。
- 点击部门右侧的 进行编辑。
- 点击部门右侧的"🚮",在出现的对话框中输入相应的部门名称,然后点击确定来删除该部门。
备注 1. 如果删除的部门包含子部门,则子部门也将被删除。 2. 部门删除后,所有部门成员的授权也将被取消。
- 0
- 0
-
赞助
 微信赞赏
微信赞赏
 支付宝赞赏
支付宝赞赏
-
分享